RAIDAR: Generative AI Detection via Rewriting¶
Authors: Chengzhi Mao, Carl Vondrick, Hao Wang, Junfeng Yang
Venue: ICLR 2024 — arXiv:2401.12970
TL;DR¶
This paper introduces Raidar, a method to detect machine-generated text by measuring how much LLMs modify text when asked to rewrite it. The key observation is that LLMs tend to preserve AI-generated text and modify human-written text more when rewriting. Using only symbolic word output and three structural properties (invariance, equivariance, uncertainty), Raidar achieves up to 29 points of F1 improvement over prior detection methods across multiple domains and is robust to adversarial rephrasing.
Contributions¶
- Identifies a fundamental asymmetry: LLMs preserve their own generated text but edit human-written text more substantially when asked to rewrite
- Proposes three measurable properties derived from this asymmetry:
- Invariance: Machine-generated text incurs smaller editing distance when rewritten
- Equivariance: Transformed inputs and reversed transformations preserve structure in machine-generated text
- Output Uncertainty: Machine-generated text shows lower variance across multiple rewriting generations
- Develops Raidar, a detection method that requires only black-box access to an LLM's symbolic output (no internal model access)
- Demonstrates robustness to adversarial prompts designed to evade detection
- Evaluates on six diverse datasets: News, creative writing, student essays, code, Yelp reviews, and arXiv abstracts
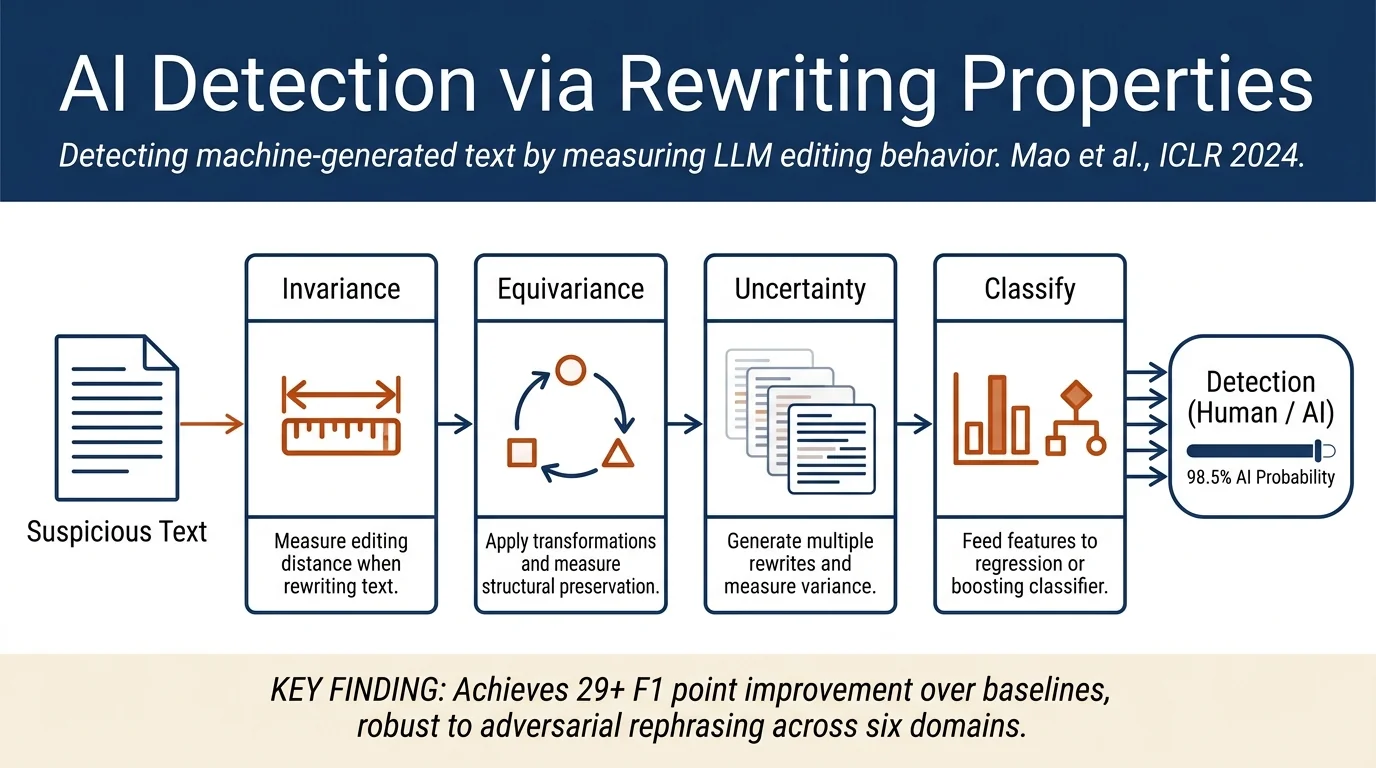
Method¶
Raidar operates in two stages: measurement and classification.
Stage 1: Measuring rewriting properties. For an input text \(x\), the method prompts an LLM to rewrite it and measures three quantities:
-
Invariance: Computes the Levenshtein distance between original and rewritten text. Machine-generated text has smaller distance (higher invariance).
-
Equivariance: Applies a transformation \(T\) (e.g., "expand this"), rewrites the transformed text, applies the reverse transformation \(T^{-1}\), and measures if the result matches direct rewriting. Machine-generated text is more equivariant.
-
Output Uncertainty: Generates multiple rewrites of the same input and measures their mutual editing distance. Machine-generated text shows lower variance.
Stage 2: Classification. Features derived from these three properties are fed to a logistic regression or XGBoost classifier trained on labeled data. The method is semantic-agnostic and requires no knowledge of the original generating model.
Results¶
In-distribution detection (Table 1): Raidar achieves substantial improvements over DetectGPT and Ghostbuster baselines: - News: 60.29 F1 (vs. 52.01 for Ghostbuster) - Creative Writing: 62.88 F1 (vs. 41.13) - Student Essay: 64.81 F1 (vs. 42.44) - Code: 95.38 F1 (vs. 65.97) - Yelp Reviews: 87.75 F1 (vs. 71.47) - arXiv Abstracts: 81.94 F1 (vs. 76.82)
Out-of-distribution robustness (Table 2): When the detector is trained on one dataset and evaluated on another, Raidar maintains strong performance (56.87 F1 on News, 59.47 on Creative Writing, 51.34 on Student Essay).
Adversarial robustness (Table 3): Against adaptive prompts designed to evade detection, multi-prompt training achieves up to 93.06 F1 on arXiv, demonstrating robustness even when adversaries know the detection mechanism.
Cross-model generalization (Table 4): The detector generalizes across different LLM sources (Ada, Text-Davinci-002, GPT-3.5-turbo, GPT-4-turbo, LLaMA 2), indicating the properties are fundamental to LLM-generated text rather than model-specific.
Connections¶
- Related to work on statistical signatures of LLM output and detection mechanisms
- Extends detection approaches pioneered in Fake news detection methods by introducing a new signal (rewriting behavior)
- Builds on prior work studying Large Language Models and their generative properties
Notes¶
Strengths: - Simple, interpretable method requiring only black-box access to any LLM - Thorough empirical evaluation across six domains with both in- and out-of-distribution testing - Explicitly addresses adversarial robustness, a critical concern for deployment - Generalization across different LLM sources suggests the underlying principles are robust
Limitations: - Requires calling an LLM multiple times to rewrite (computational overhead) - The choice of rewriting prompts appears manually crafted; unclear if prompt engineering is needed for new domains - No theoretical justification for why these three properties should distinguish human from machine text - Limited analysis of failure cases or domains where the method may struggle
Future directions: - Automatic prompt discovery instead of manual design - Theoretical analysis of when and why the invariance/equivariance properties hold - Extension to multimodal or non-English content - Evaluation against future LLM architectures as models evolve