TELLER: A Trustworthy Framework For Explainable, Generalizable and Controllable Fake News Detection¶
Authors: Hui Liu, Wenya Wang, Haoru Li, Haoliang Li Venue: arXiv preprint — 2402.07776
TL;DR¶
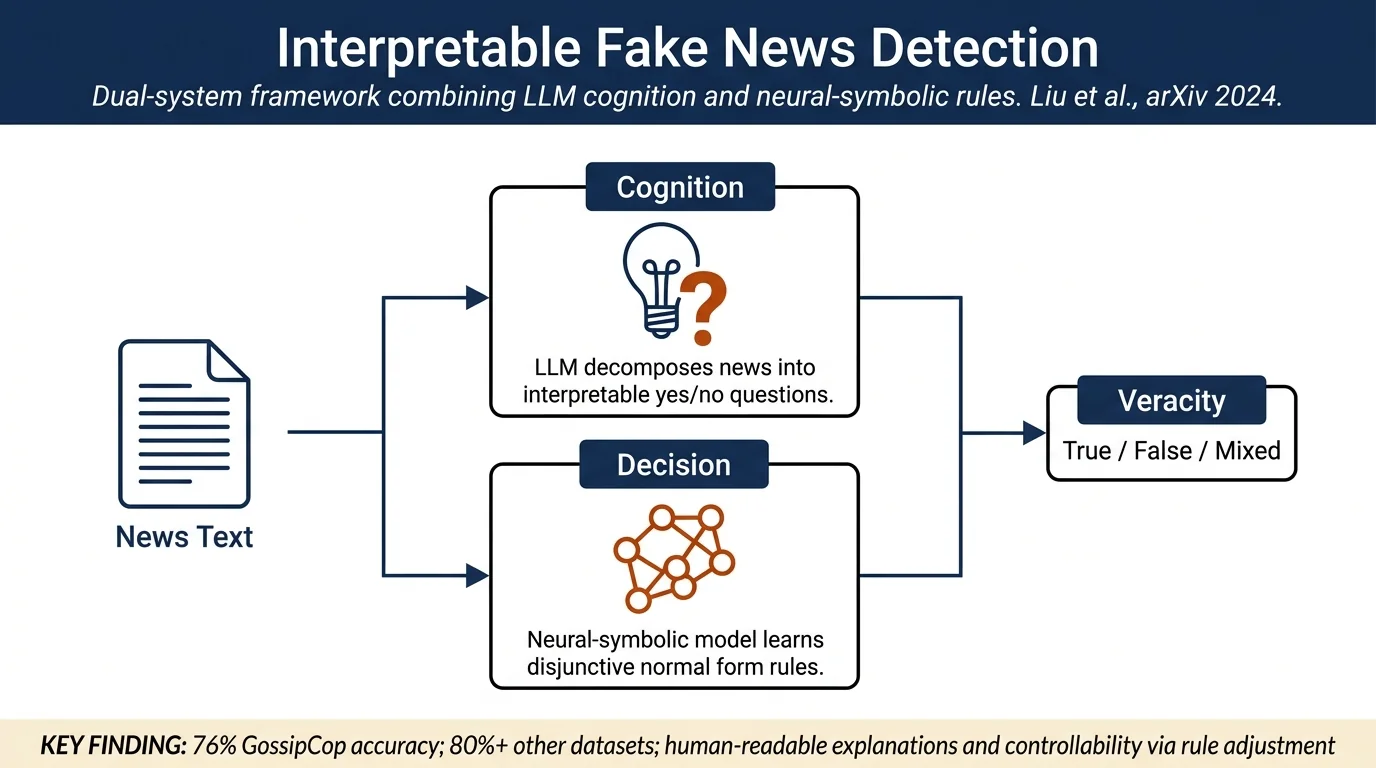
TELLER proposes a dual-system framework for fake news detection that combines LLM-driven cognition (decomposing content into yes/no questions) with a neural-symbolic decision system (learning interpretable rules). The approach prioritizes explainability, generalizability, and human controllability, achieving 76% accuracy on GossipCop and over 80% on three other datasets while maintaining transparency in decision-making.
Contributions¶
- A systematic framework (TELLER) for trustworthy fake news detection that operationalizes explainability, generalizability, and controllability as design principles.
- A dual-system architecture: a cognition system that decomposes human fact-checking expertise into logical predicates via LLMs, and a decision system that learns interpretable rules via a neural-symbolic model (Disjunctive Normal Form layer).
- Comprehensive empirical evaluation on four datasets (LIAR, Constraint, PolitiFact, GossipCop) demonstrating feasibility, explainability, generalizability, and controllability.
- Demonstration that the framework outperforms direct LLM prompting and enables human intervention through rule adjustment.
Method¶
Cognition System¶
The cognition system mimics human fact-checking by decomposing the detection problem into interpretable yes/no questions. Using LLMs (FLAN-T5, Llama2, GPT-3.5-turbo), the system:
- Generates a set of question templates Q from human expertise, where each template Qᵢ corresponds to a logical predicate Pᵢ
- For input news T, instantiates these templates with concrete claims extracted from T to form logic atoms
- Computes truth values μᵢ for each logic atom by querying the LLM
The paper proposes two strategies for obtaining truth values: - For open-vocabulary LLMs (FLAN-T5, Llama2): sample m times and count affirmative responses - For closed-vocabulary LLMs (GPT-3.5-turbo): use post-softmax logits to mitigate irrelevant token influence
Decision System¶
The decision system learns to aggregate logic atom truth values into a final veracity prediction using a neural-symbolic approach:
- Stacks C conjunctive layers (Sᴸ∧) and J disjunctive layers (Sᴸ∨) in alternation, with each layer corresponding to a truthfulness label
- Each Sᴸ∨ learns a conjunction of logic atoms corresponding to a candidate rule
- The final DNF Layer applies softmax to produce probability distribution over labels
The decision system can learn disjunctive normal form rules end-to-end (e.g., "label true if rule₁₂₃ OR rule₂₇ is true"), enabling both interpretability and error correction of imperfect LLM predictions.
Results¶
Binary classification (Closed-domain): - TELLER achieves 76.53% accuracy on GossipCop (closed setting) - Over 80% accuracy on Constraint, PolitiFact, and LIAR - Outperforms GPT-3.5-turbo Direct prompting by significant margins - F1 scores exceed Direct by average of 7% and 6% in respective settings
Cross-domain generalization: - Consistently outperforms Direct prompting across all four datasets with no generalization algorithm - Negligible performance drop compared to in-domain training
Multi-classification (LIAR fine-grained labels): - Framework forms Direct for FLAN-T5 and Llama2 series, demonstrating robustness to noisy LLM predictions
Explainability: - Questions and logic atoms are human-readable and verifiable - Learned DNF rules are interpretable and can be manually adjusted - Symbolic components enable identification of which questions drove decisions
Controllability: - Manual adjustment of DNF Layer weights enables human intervention - Demonstrates feasibility of human experts correcting misaligned rules - Intervention experiments show consistent improvement when adjusting low-confidence predictions
Connections¶
- Related to Fake news detection methods through neural-symbolic approaches combining neural and logical components
- Addresses Explainable AI concerns in fake news detection systems
- Builds on Trustworthy AI frameworks that emphasize transparency and human oversight
- Complements Fact-checking and corrections systems by decomposing verification into interpretable steps
- Uses Neural-symbolic AI models for interpretable decision-making
Notes¶
Strengths: - Novel approach to explainability through decomposed questions rather than post-hoc explanations - Systematic treatment of three critical aspects (explainability, generalizability, controllability) - Strong empirical results across diverse datasets and LLMs - Human-in-the-loop capability through rule adjustment - Practical applicability—the cognition system can leverage different LLMs
Limitations acknowledged: - Trustworthiness limited to algorithmic design; data collection and deployment governance remain open - Integrating external knowledge sources improved performance but added complexity - DNF Layer expressiveness constrained by simple architecture; more sophisticated decision models could enhance results - Trade-off between trustworthiness and decision system complexity
Open questions: - How does performance scale as question template sets grow? - What is the optimal level of human expert involvement for practical deployment? - Can the framework extend to real-time or streaming fact-checking scenarios?