Explainable Claim Verification via Knowledge-Grounded Reasoning with Large Language Models¶
Authors: Haoran Wang, Kai Shu Affiliation: Illinois Institute of Technology, Chicago, IL, USA ArXiv: 2310.05253
TL;DR¶
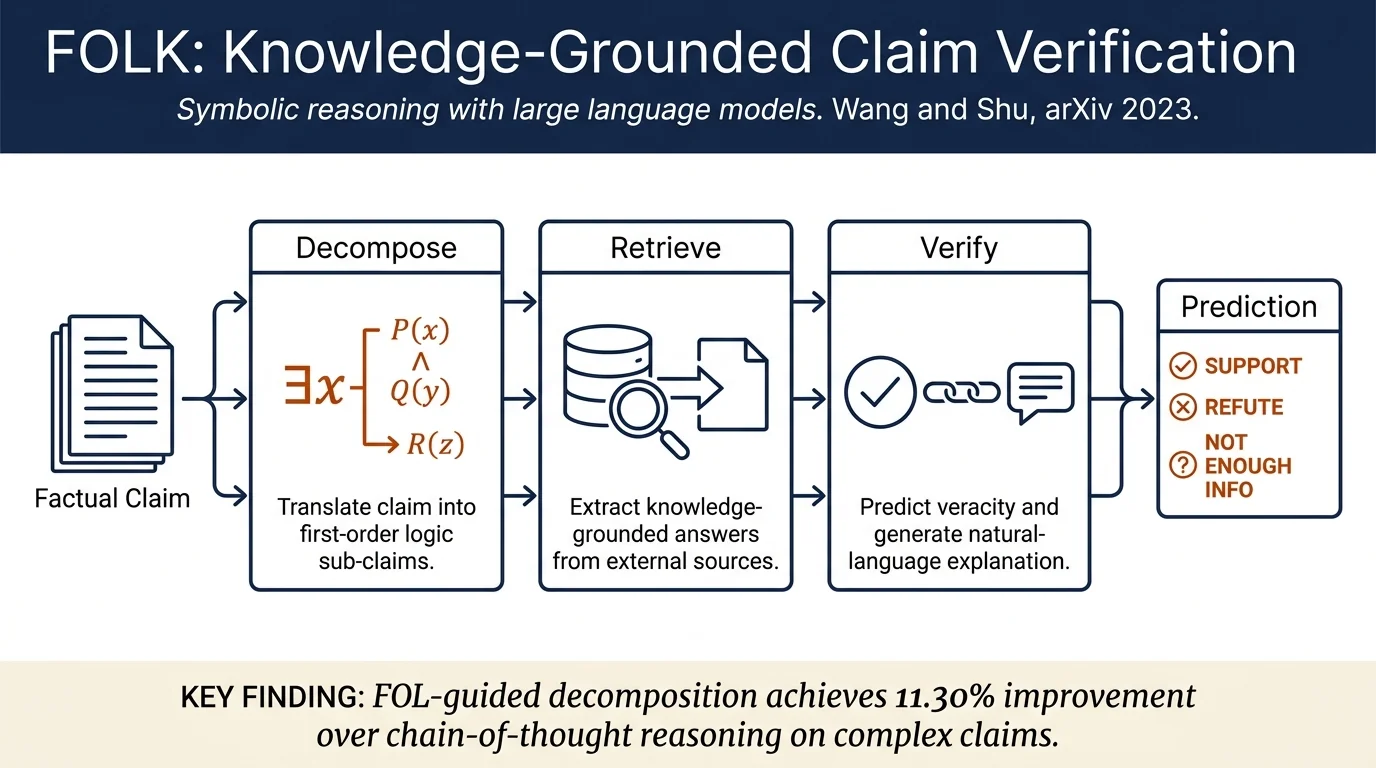
This paper introduces FOLK (First-Order-Logic-Guided Knowledge-Grounded Reasoning), a method for verifying factual claims and generating explanations without requiring annotated evidence. FOLK translates claims into first-order logic predicates to decompose them into verifiable sub-claims, then uses LLMs to retrieve and reason over knowledge-grounded answers. Evaluated on three datasets (HoVER, FEVEROUS, SciFactOpen), FOLK achieves state-of-the-art performance while providing human-readable explanations that outperform baselines in coverage and readability.
Contributions¶
- A novel framework that verifies claims without annotated evidence while generating comprehensive explanations
- Demonstration of FOL-guided claim decomposition as a more effective reasoning strategy than chain-of-thought prompting
- Evidence that knowledge-grounding (external retrieval) significantly improves claim verification accuracy over relying solely on LLM internal knowledge
- High-quality explanation generation with strong inter-annotator agreement (κ > 0.67 across evaluation criteria)
Method¶
FOLK consists of three stages:
1. FOL-Guided Claim Decomposition The method first translates an input claim into First-Order-Logic (FOL) predicates, decomposing it into constituent sub-claims. For example, "Tomás Smid and Fabricio Santoro were both American tennis players" becomes a FOL clause with predicates checking nationality and profession. This symbolic representation allows systematic decomposition.
2. Knowledge-Grounded Answer Retrieval For each decomposed predicate, FOLK generates intermediate question-answer pairs. LLMs are prompted to retrieve knowledge-grounded answers from external sources (Google Search via SerPAPI). This grounds the reasoning in external knowledge rather than relying solely on LLM hallucination-prone internal knowledge.
3. Veracity Prediction and Explanation Generation Given the knowledge-grounded answers for all predicates, FOLK evaluates the FOL clause to make a final veracity prediction (SUPPORT, REFUTE, or NOT ENOUGH INFO). The intermediate questions, answers, and reasoning steps are used to generate natural-language explanations that justify the decision.
Results¶
Macro F1 scores on three benchmark datasets:
HoVER (multi-hop reasoning): - 2-hop: 66.26% (vs. 71.00% ProgramFC baseline) - 3-hop: 54.80% (vs. 51.04% ProgramFC) - 4-hop: 60.35% (vs. 52.92% ProgramFC)
FEVEROUS (structured + unstructured data): - Numerical reasoning: 59.49% (vs. 54.78% ProgramFC) - Multi-hop reasoning: 67.01% (vs. 59.84% ProgramFC) - Text and table reasoning: 63.42% (vs. 51.69% ProgramFC)
SciFactOpen (domain-specific scientific claims): - 67.59% (vs. 49.70% Direct baseline)
FOLK outperforms all baselines on 6 of 7 evaluation tasks. Key findings: (1) FOL-guided decomposition shows 11.30% average improvement over chain-of-thought, particularly on complex claims (12.13% improvement on 3-hop claims); (2) knowledge-grounded answers substantially improve reasoning—using only Wikipedia reduces performance compared to using Google Search; (3) explanations generated by FOLK receive the best ratings for coverage (1.57 MAR), soundness (1.07 MAR), and readability (1.27 MAR) compared to baselines.
Connections¶
- Related to Claim Verification as a core method for automated fact-checking
- Uses large language model capabilities for reasoning and explanation generation
- Implements explainable AI principles by generating justified decisions
- Employs knowledge grounding to reduce LLM hallucination
- Applies Natural Language Inference for semantic reasoning
- Relevant to Multi Hop Reasoning datasets like Hover and Feverous
Notes¶
Strengths: - Novel application of symbolic reasoning (FOL) to guide neural LLM behavior—bridges classical AI and modern language models - Comprehensive evaluation across three diverse datasets spanning multi-hop, numerical, and scientific reasoning - Rigorous manual evaluation of explanation quality by three annotators with reasonable inter-rater agreement - Achieves competitive results on smaller LLMs (llama-13B, llama-30B), suggesting practical applicability beyond massive models - Honest discussion of computational cost ($20 per 100 examples via OpenAI API) and environmental impact
Limitations: - Synthetic claims in experiments can be decomposed with explicit reasoning structure; real-world claims often have implicit semantic structure requiring more sophisticated reasoning - Requires knowledge sources accessible to the retrieval module; performance depends significantly on retrieval quality (shown in ablation: wikipedia-only substantially underperforms) - Higher computational cost than supervised baselines—claims the method is expensive compared to traditional fact-checking pipelines
Open Questions: - How would FOLK perform on adversarial claims designed to evade symbolic decomposition? - Could the approach generalize to other structured-reasoning tasks beyond claim verification? - What is the performance ceiling when knowledge retrieval is imperfect or unavailable for emerging events?