Can AI-Generated Text be Reliably Detected?¶
Authors: Vinu Sankar Sadasivan, Aounon Kumar, Sriram Balasubramanian, Wenxiao Wang, Soheil Feizi
Venue: arXiv, 2023 — 2303.11156
TL;DR¶
This paper stress-tests AI-text detectors using a novel recursive paraphrasing attack, showing that watermarking-based, neural network-based, and retrieval-based detectors can be reliably broken with only minor text degradation. The work establishes a theoretical connection between detector AUROC and the total variation distance between human and AI-generated text distributions, revealing a fundamental hardness result for reliable detection as language models improve.
Contributions¶
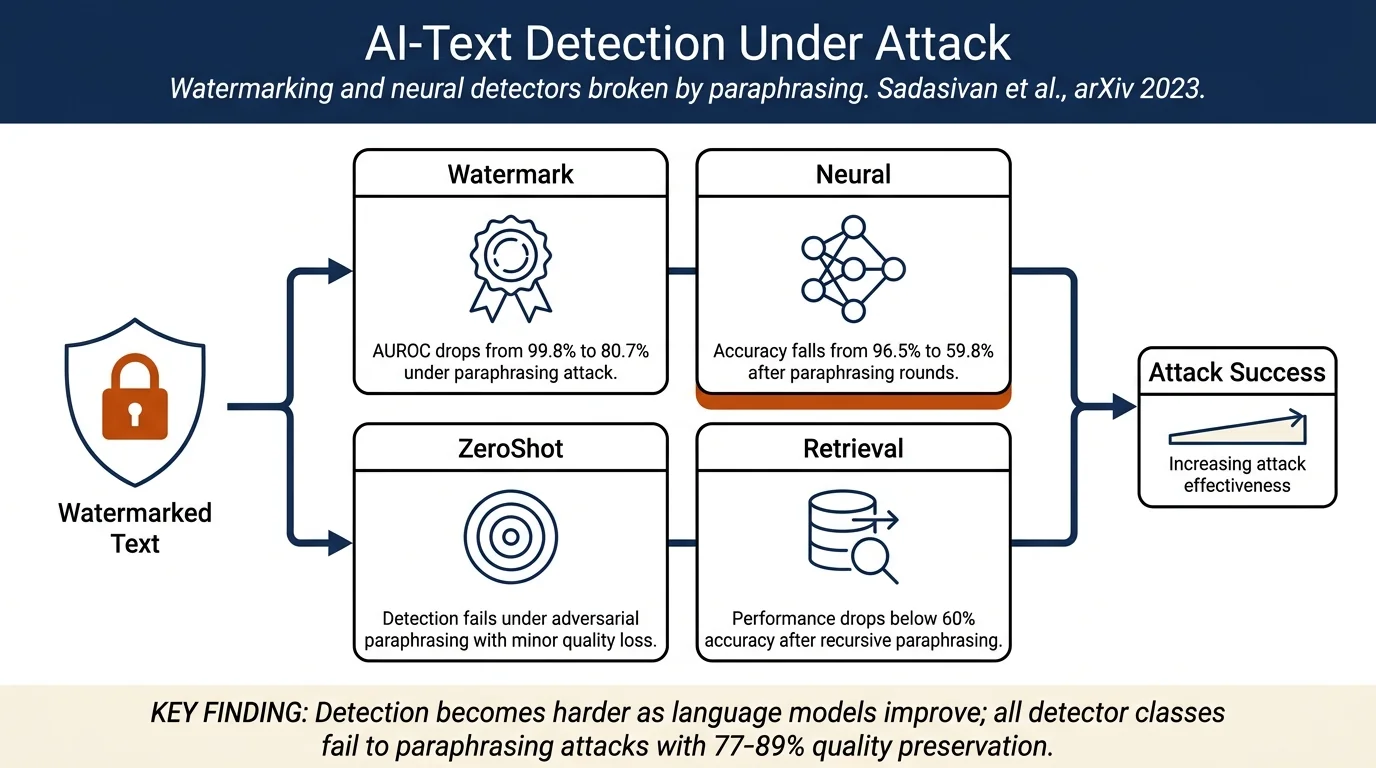
- Comprehensive analysis of robustness for four classes of AI-text detectors: watermarking, neural network-based, zero-shot, and retrieval-based methods
- Introduction of a recursive paraphrasing attack that breaks watermarking and retrieval-based detectors while preserving text quality in 77-89% of cases
- Demonstration of spoofing attacks where adversaries can cause detectors to flag human-written text as AI-generated (type-I errors)
- Theoretical framework proving that detector AUROC is bounded by total variation distance between human and AI-text distributions
- Evidence that improved language models lead to smaller distribution distances, making reliable detection increasingly difficult
Method¶
The attack uses neural paraphrasers (DIPPER, LLaMA-2-7B-Chat, T5-based) to recursively rewrite watermarked or generated text. Experiments test on 1000 long news articles (~300 tokens each) from the XSum dataset, evaluating multiple target LLMs including OPT-13B and GPT-2 Medium. The authors measure attack success via ROC curves and perplexity-based text quality metrics, along with human evaluation studies.
Results¶
On watermarked OPT-13B, the recursive paraphrasing attack reduces watermark detector AUROC from 99.8% to 80.7% in five rounds. Zero-shot detectors drop from 96.5% to 59.8%. Retrieval-based detectors fall below 60% accuracy after five paraphrasing rounds. Spoofing attacks can cause detector AUROC to drop from 99.8% to 1.3% on soft-watermarked text. Human studies show 77% of recursively paraphrased passages maintain high content quality and 89% preserve grammar, indicating practical attack feasibility.
The paper also shows that detection becomes harder as language models improve: better models generate text closer to human distributions, reducing the total variation distance and making discrimination mathematically harder.
Connections¶
- Related to Adversarial Machine Learning through the evasion attack framework
- Builds on Watermarking defense mechanisms and their vulnerabilities
- Connected to Language Models robustness and alignment challenges
- Relevant to AI-Generated Text Detection as a fundamental limitations paper
Notes¶
The theoretical result (Theorem 1) is notable: it rigorously bounds the best-possible detector's AUROC in terms of total variation distance between text distributions. This has implications for detection research—as language models become more capable and their outputs approach human text distributions, reliable detection becomes provably harder. The finding that watermarking can be spoofed through paraphrasing without white-box access is particularly concerning for systems relying on watermarks for authentication. The slight text quality degradation (perplexity increases modestly) makes the attack practical for adversaries willing to accept minor quality loss.