The Perils & Promises of Fact-checking with Large Language Models¶
Authors: Dorian Quelle, Alexandre Bovet Affiliation: Department of Mathematical Modeling and Machine Learning, Digital Society Initiative, University of Zurich arXiv: 2310.13549 Date: October 2023
TL;DR¶
This paper evaluates GPT-3.5 and GPT-4's ability to fact-check claims across English-only and multilingual datasets, showing GPT-4 substantially outperforms GPT-3.5 but both models show inconsistent accuracy when dealing with ambiguous verdicts. Critically, incorporating contextual information via Google Search significantly improves performance, yet models remain vulnerable to language effects—non-English claims translated to English achieve higher accuracy, suggesting training data dominance of English severely impacts multilingual verification capacity.
Contributions¶
- Novel benchmarking methodology: Evaluates GPT-3.5 and GPT-4 on automated fact-checking using a ReAct agent framework enabling iterative web search and reasoning, grounding each verdict with cited sources
- Evidence retrieval integration: Demonstrates that providing external evidence from Google Search substantially improves both model accuracy and calibration, with accuracy gains of 10–20 percentage points across conditions
- Large-scale multilingual evaluation: First assessment of GPT-3.5's multilingual fact-checking capability across 16+ languages from Data Commons, revealing critical language-specific performance disparities
- Temporal analysis: Documents accuracy trends over time (2011–2023) for both models, showing improvement trajectories when new information becomes available via Google
- Data leakage risk assessment: Identifies that GPT-4's training data includes web-crawled content and fact-checking websites, creating both opportunities (understanding of check-worthiness) and risks (potential memorization of verdicts)
Method¶
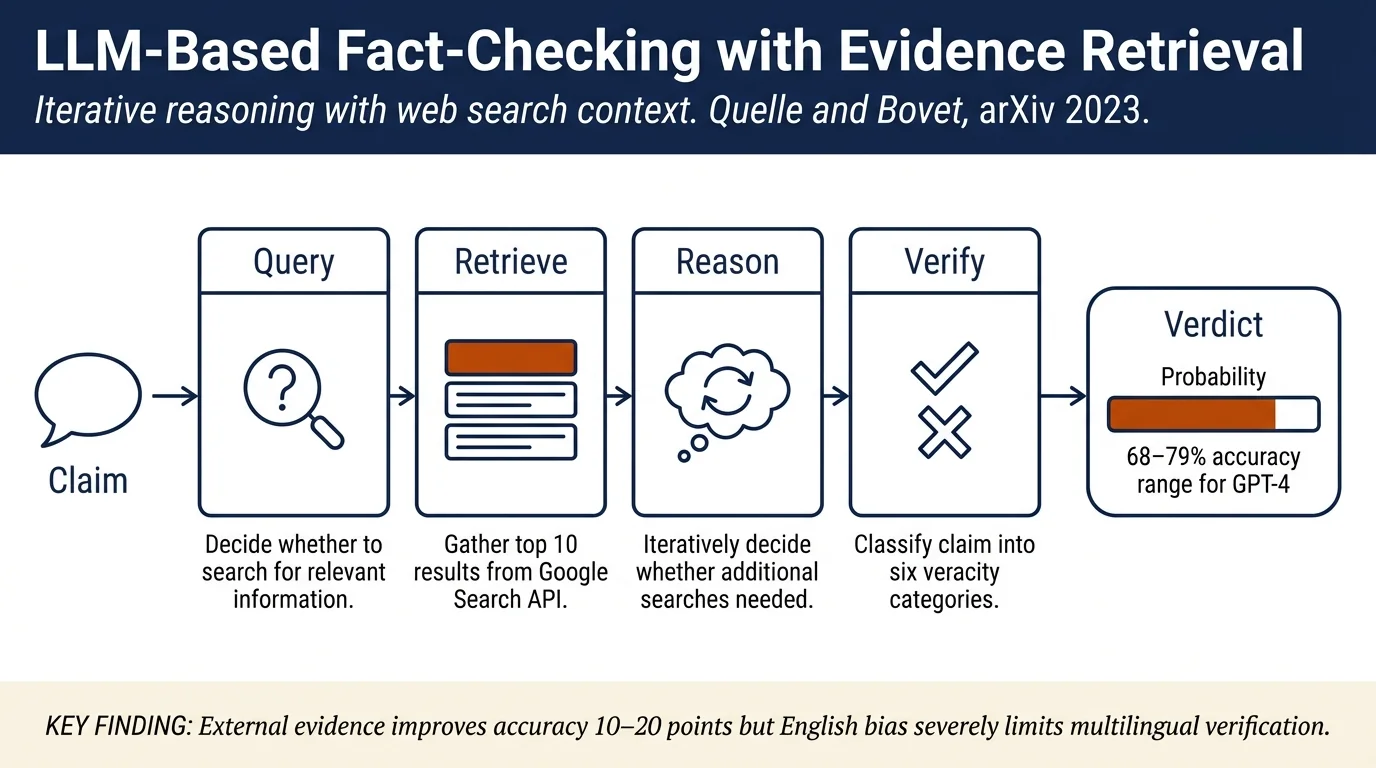
The authors use a ReAct (Reasoning + Acting) framework where LLMs serve as agents capable of: - Formulating queries: Given a claim (statement, author, date), the agent decides whether to issue web search queries - Retrieving contextual information: Using Google Search API and the BM25 retrieval framework to gather 10 top search results per iteration - Making verdicts: Classifying claims into ordinal categories (True, Mostly-True, Half-True, Mostly-False, False, Pants-Fire) with explanations - Iterative reasoning: The agent decides whether to perform additional searches (up to 10 iterations) or return a final verdict
Datasets: 1. PolitiFact dataset: 3,000 unique fact-checked claims from PolitiFact with six veracity categories (sampled equally from 2007–2022). Compared with and without Google search context. 2. Data Commons multilingual dataset: Multi-lingual fact-checks from 78+ fact-checking organizations across 16+ languages, with ~500 claims per language where available. Evaluated with and without context, and in original language vs. English translation.
Baselines and Comparisons: - GPT-3.5 (with and without context) - GPT-4 (with and without context) - Models' accuracy is computed against ground-truth labels from human fact-checkers
Results¶
Experiment 1: PolitiFact Dataset¶
Without Context: - GPT-4 achieves 68.5% overall accuracy (grouping Pants-Fire/False/Mostly-False as False; True/Mostly-True as True) - GPT-3.5 achieves 62.0% overall accuracy - Gap is larger for true verdicts (true-label categories: GPT-4 at 49.1%, GPT-3.5 at 40.9%) than false verdicts
With Context (Google Search): - GPT-4 improves to 79.3% accuracy - GPT-3.5 improves to 71.4% accuracy - Both models exhibit improved calibration on ambiguous categories (half-true, mostly-true/mostly-false) - Context substantially helps models distinguish between edge cases
Accuracy Over Time: - Both models show upward performance trends from 2011 to 2023 - GPT-4 maintains consistent advantage over GPT-3.5 across years - No sudden drop after official GPT-3.5 training cutoff (September 2021), suggesting either incremental knowledge updates or robust generalization to post-training-date claims
Experiment 2: Multilingual Data Commons Dataset¶
English Performance (without context): - GPT-3.5: 68.28% accuracy, 71.06 F1 score - GPT-4: 68.65% accuracy, 71.96 F1 score
Non-English Performance (without context): - Dramatic performance drops for most non-English languages - Turkish: GPT-3.5 at 84.19% accuracy (English), 81.50% (Multilingual) - Indonesian: GPT-3.5 at 86.68% (English), 84.59% (Multilingual) - French: GPT-3.5 at 74.67% (English), 81.67% (Multilingual—note improvement, likely due to high-resource language training) - Thai: GPT-3.5 at 48.21% (English), 54.34% (Multilingual) - Languages with <50 observations and low baseline performance were excluded
Key Finding: Language Translation Effect - When non-English claims are translated to English before submission to models: - Accuracy improves by 5–20+ percentage points for most languages - Example: Persian F1 score improves from 56.51 (original) to 70.65 (English translation) - This demonstrates clear training data bias toward English and limitations in handling non-English linguistic variation
With Context (multilingual): - Context retrieval substantially improves performance across all languages - English condition with context: GPT-3.5 at 87.42% accuracy - Multilingual with context: GPT-3.5 at 89.21% accuracy (still lower than English) - Context helps close but does not eliminate the English-superiority gap
Temporal trends (Data Commons): - Similar upward trend visible from 2020–2023 - No significant drop after GPT-3.5's training cutoff, consistent with PolitiFact findings
Connections¶
- Related to Language model truthfulness which documents broader questions of LLM honesty and hallucination tendencies
- Extends LLM-based detection and analysis methodology by showing evidence integration improves LLM-driven fact verification
- Relevant to Computational fact checking as evidence-based automation alternative to knowledge-graph methods
- Cited by later work on Claim Verification using transformer architectures and retrieval-augmented generation
- Informs Multilingual Misinformation research by documenting performance disparities and training-data biases in non-English contexts
Notes¶
Strengths: - Transparent methodology: Full transcripts of Google queries, retrieval results, and model reasoning shown in figures and supplementary materials—enables reproducibility and error analysis - Both theoretical and practical: Explores fundamental limitations (data leakage, translation effects) while providing actionable insights for practitioners - Comprehensive multilingual scope: 16+ languages from real fact-checking organizations (not synthetic) with significant volume per language - Temporal grounding: Shows how models perform on claims from before/after their training cutoff, revealing that improvement over time likely stems from available search evidence rather than training memorization - Honest about limitations: Authors explicitly discuss "perils" including data leakage risks and continued dependence on human fact-checkers
Weaknesses: - Accuracy still far from practical deployment: Even GPT-4 with context achieves only ~80% accuracy on PolitiFact; ambiguous categories remain hard to distinguish, limiting real-world utility - Limited to two models: GPT-3.5 and GPT-4 only; does not compare with other LLMs (Claude, Llama, Gemini) or task-specific fact-checking models (DeBERTa-based approaches) - Search dependency: Results heavily depend on Google Search quality and availability—geographically restricted and may skew toward English-language sources - Dataset imbalance: Data Commons has varying sample sizes per language (98–500 claims); smaller languages underrepresented in analysis - Verdicts are heterogeneous: Different fact-checking organizations use different label schemas; standardization to 4–6 categories loses nuance and may introduce label noise
Follow-up opportunities: - Compare against evidence-augmented specialized models (e.g., DeBERTa fine-tuned on FEVER or MultiFC) to isolate the performance difference due to model architecture vs. retrieval strategy - Investigate fine-tuning GPT models on multilingual fact-checks to reduce language bias - Develop cost-effective strategies for extending fact-checking to truly low-resource languages (Swahili, Somali, etc.) where Google Search coverage is sparse - Explore hybrid human-AI workflows where models identify check-worthy claims but humans make final verdicts—potentially more practical than full automation - Longitudinal analysis: as newer GPT models (GPT-4 Turbo, GPT-5) emerge, document whether training data diversification improves non-English performance