A Watermark for Large Language Models¶
Authors: John Kirchenbauer, Jonas Geiping, Yuxin Wen, Jonathan Katz, Ian Miers, Tom Goldstein
Venue: arXiv preprint, 2023 — 2301.10226
TL;DR¶
Proposes a watermarking scheme for large language models that embeds imperceptible signals into generated text, enabling detection of machine-generated content without access to model parameters or APIs. The watermark works by promoting a randomized set of "green" tokens during decoding and can be detected using a statistical z-test; the scheme remains robust against various attack strategies including paraphrasing, token substitution, and text editing.
Contributions¶
- A watermarking framework that embeds signals in LLM output without degrading text quality
- Two variants: a simple "hard" red-list rule and a more sophisticated "soft" rule adaptive to text entropy
- An efficient, open-source detection algorithm requiring no model access
- Theoretical analysis using spike entropy to characterize watermark robustness
- Empirical evaluation of detection under various attack scenarios (paraphrasing, insertions, deletions, substitutions)
Method¶
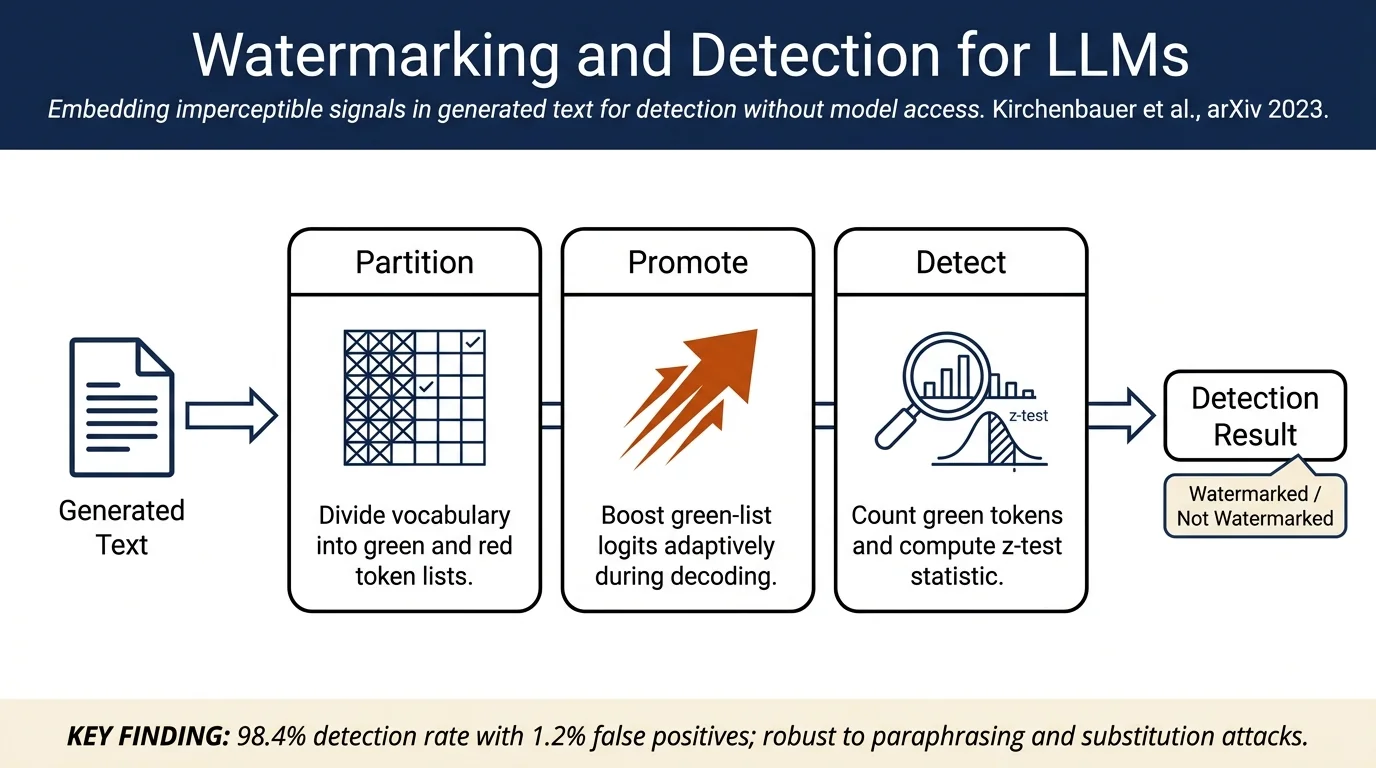
The watermarking scheme partitions the vocabulary into "green" and "red" token lists using a hash function and random seed. During decoding, the model's output distribution is modified by adding a constant δ to green-list logits. Two variants are proposed:
Hard red-list watermark: Green tokens are promoted via a multiplicative factor. When the probability of a green token exceeds a threshold, it is sampled; otherwise, tokens are drawn from the "red" list. This approach handles low-entropy sequences simply but prevents natural text generation when entropy is low.
Soft red-list watermark: Adaptively applies the green-list promotion rule only when sufficient entropy is available. The rule parameter γ controls the green-list size, and a "strength" parameter δ tunes the logit offset. Detection uses a one-proportion z-test: if the observed proportion of green tokens has a z-score exceeding a threshold (typically z = 4), the text is flagged as watermarked.
The scheme supports private watermarking using a pseudorandom function and a secret key, enabling watermark verification behind a secure API without exposing the watermarking algorithm itself. Multiple hidden keys can be used to boost brute-force resistance.
Results¶
Detection performance: For text of length T = 200 ± 5 tokens with multinomial sampling, 98.4% of generations are detected at a false-positive rate of 1.2% using z = 4. Beam search with greedy decoding achieves 99.6% empirical sensitivity and near-zero false-positive rates.
Robustness under attack: Testing against five attack categories—paraphrasing, text insertion, deletion, substitution, and tokenization—shows the watermark degrades gracefully. Paraphrasing attacks reduce detection rate only minimally. Span-replacement attacks (inserting/replacing spans using a language model) are the strongest attack, requiring modification of ~25% of tokens to achieve significant watermark removal while maintaining semantic similarity.
Watermark strength vs. quality tradeoff: Increasing the green-list size γ and strength δ strengthens the watermark but can reduce perplexity. The tradeoff is explored systematically, showing that reasonable parameter choices (γ = 0.5, δ = 2.0) achieve strong detection with minimal quality impact.
False positives: The scheme produces no false positives for human-written text under standard test conditions, and the theoretical framework predicts false-positive rates near zero given the randomized green-list construction.
Connections¶
- Related to Fake news detection methods for identifying synthetic text
- Shares theoretical framework with steganography and information-hiding approaches for embedding hidden information
- Complements post-hoc detection methods that analyze generated text without watermarks
- Addresses broader debates on synthetic data and LLM harms in the research literature
Notes¶
Strengths: The scheme is elegant and practical—watermarks can be added to any existing LLM without retraining, detection is computationally efficient, and the theoretical analysis (via spike entropy) provides principled insights into robustness. The empirical evaluation is thorough, testing multiple sampling strategies and realistic attacks.
Limitations: Low-entropy text sequences (e.g., code, mathematics, repetitive content) are harder to watermark without quality degradation. Sophisticated attacks (especially paraphrasing or span replacement using external models) can remove watermarks at the cost of some perplexity. The detector requires a contiguous text span (at least ~25 tokens) to reliably detect the watermark, limiting applicability to very short texts. Users with access to a private watermarking model but not the public version face asymmetric advantage.
Follow-up questions: How does the scheme perform on domain-specific text (legal documents, scientific writing)? Can watermarks persist across summarization or translation? How should the framework scale to billion-parameter models and more sophisticated prompt-based attacks?