Generative Language Models and Automated Influence Operations: Emerging Threats and Potential Mitigations¶
Authors: Josh A. Goldstein, Girish Sastry, Micah Musser, Renée DiResta, Matthew Gentzel, Katerina Sedova
Affiliations: Georgetown University's Center for Security and Emerging Technology, OpenAI, Stanford Internet Observatory
Published: January 2023 — arXiv:2301.04246
TL;DR¶
Generative language models like GPT-3 and ChatGPT could significantly expand the scale and scope of influence operations by automating high-quality propaganda generation, lowering barriers to entry for new propagandists, and enabling novel tactics. The authors use an Actor-Behavior-Content (ABC) framework to identify how these models threaten future information ecosystems, then map mitigations across four intervention points: model design & construction, model access, content dissemination, and belief formation.
Contributions¶
-
Threat analysis through ABC framework: Examines how language models affect which actors can wage influence operations (lowering costs, expanding pool), how they do so (automating content, enabling new tactics), and what content they produce (more credible, less detectable).
-
Critical unknowns: Identifies key uncertainties that will shape actual impact: whether new influence capabilities emerge in practice, whether actors invest in models for propaganda, whether norms constrain deployment, when easy-to-use tools become publicly available.
-
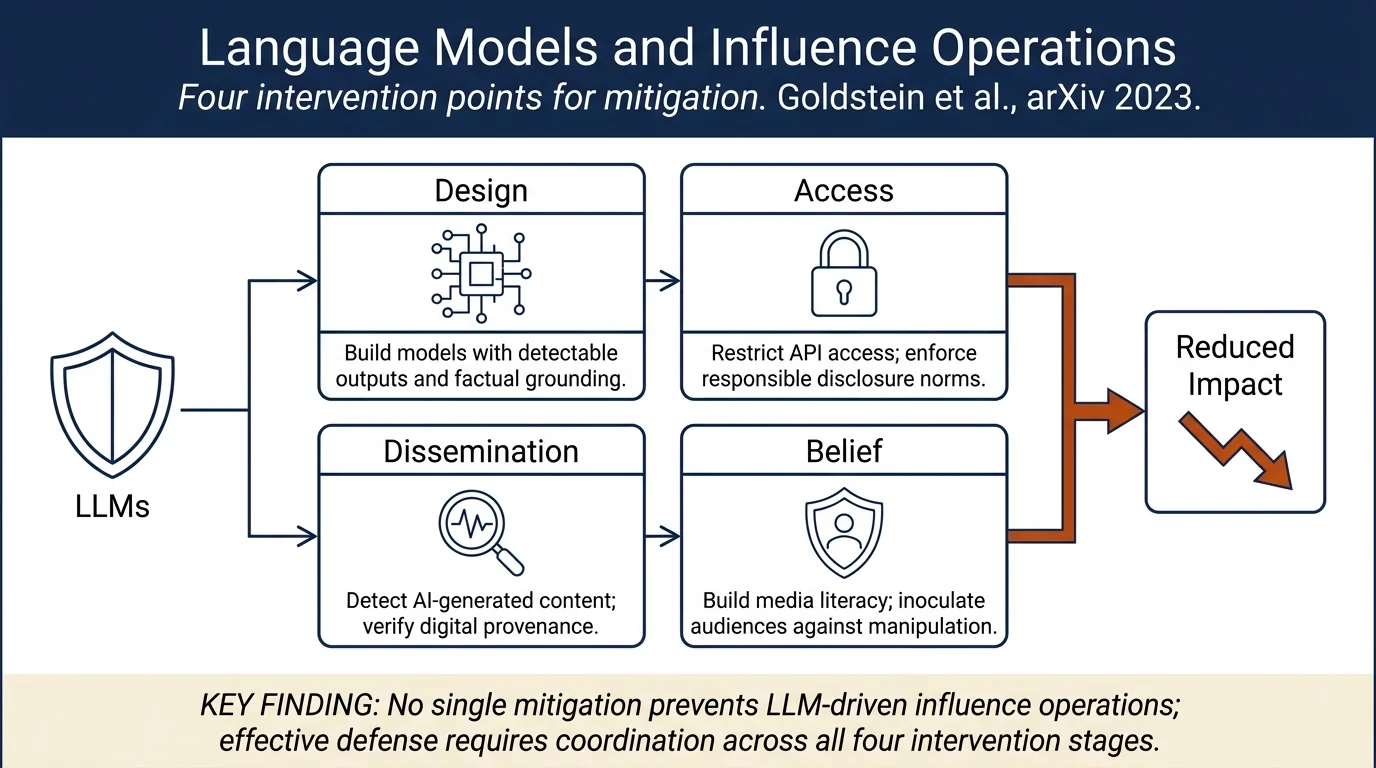
Comprehensive mitigation taxonomy: Proposes mitigations spanning four stages of the influence operation pipeline, evaluated against technical feasibility, social feasibility, downside risk, and impact. No single mitigation fully addresses the threat; a multi-stakeholder approach is necessary.
-
Workshop-informed analysis: Synthesizes insights from 30+ experts in disinformation, AI, and policy to ground speculation in current understanding of both threat vectors and practical constraints.
The Threat: Language Models and Influence Operations¶
Language models could impact influence operations across three dimensions (adapted from Camille François's disinformation ABC framework):
Actors: By automating propaganda generation, language models lower the cost barrier to entry. More actors—including smaller entities and outsourced firms—could wage influence operations. Propagandists-for-hire that commodify text generation may gain competitive advantages.
Behavior: Influence operations become easier to scale when content production is automated. Existing tactics (e.g., cross-platform campaigns, spear-phishing) become cheaper. Novel tactics emerge: personalized, real-time content generation; dynamic, conversational manipulation via chatbots; targeted messaging tailored to individual user profiles.
Content: Language models may produce more credible and persuasive messaging than propagandists who lack linguistic or cultural knowledge of their targets. Generated content is harder to detect and fact-check because it does not rely on copy-pasted text (a signature detection method). However, for disinfo to work, it must have a kernel of truth—models can amplify existing narratives but cannot create belief from nothing.
Method¶
The authors build on a workshop convened in October 2021 with 30+ experts across AI, influence operations, and policy. They synthesize existing literature on influence operations, generative models, and disinformation mitigations, then design a mitigation framework organized around four stages of an influence operation pipeline:
- Model Design and Construction: How can language models be built to resist misuse?
- Model Access: How can access to capable models be restricted or monitored?
- Content Dissemination: How can AI-generated propaganda be detected and slowed?
- Belief Formation: How can target audiences be inoculated or protected?
For each mitigation, they assess technical feasibility (can it be implemented?), social feasibility (can it survive political and institutional scrutiny?), downside risk (what harms might it cause?), and impact (how effective would it be?).
Mitigations and Their Constraints¶
Model Design & Construction mitigations include building models with more detectable outputs (e.g., via "radioactive data" watermarking), designing models to be more factually grounded, restricting access to training data, and imposing hardware controls. These are technically challenging, require coordination across developers, and may only partially succeed: adversaries can gravitate to unrestricted models.
Model Access mitigations rely on API restrictions, responsible disclosure norms, and security hardening. They face the collective action problem: effective only if all AI providers enforce restrictions, and if open-source models remain powerful, bad actors can use public versions.
Content Dissemination mitigations include platform-AI company coordination to detect AI-generated content, proof-of-personhood requirements to post, and digital provenance standards. Detection remains an open problem; linguistic and metadata signals degrade as models improve. Platforms struggle to identify synthetic content at scale.
Belief Formation mitigations focus on media literacy, consumer-focused AI tools, and institutional guardrails. These address demand-side resistance and may complement supply-side controls, but are slower and harder to measure than technical interventions.
Key Findings¶
-
No single mitigation will fully prevent language models from being used in influence operations. A "whole of society" approach is necessary.
-
Most mitigations face the collective action problem: their effectiveness depends on coordination among AI developers, platforms, governments, and civil society, each with different incentives.
-
Critical unknowns remain about adoption, efficacy, and norm-setting. Researchers and policymakers must prepare for multiple scenarios while remaining humble about what we cannot yet predict.
-
Mitigations also risk unintended consequences: overly aggressive content restrictions may chill legitimate speech; hardware controls could escalate geopolitical tensions; fact-sensitizing models may paradoxically make propaganda more persuasive.
-
International coordination and norm-building are essential but difficult; different countries have competing interests in AI development and information control.
Connections¶
- Influence Operations — central topic; this paper applies threat modeling to a novel technology vector
- Propaganda — traditional propaganda tactics; language models lower cost and scale
- Disinformation — AI-generated false content; complements human-authored disinformation
- AI-Generated Content — broader category; this paper narrows focus to text and influence use cases
- Content moderation — detection and mitigation of harmful content on platforms
- Media literacy — one mitigation strategy; teaches audiences to resist influence
- Bot detection — related technical challenge; identifying automated accounts; language models may improve chatbot sophistication
- Deepfakes — parallel threat with multimodal generative models; similar mitigation principles apply
- Trustworthiness Language Models — technical approach to building safer models; directly relevant to model design mitigations
Notes¶
This is one of the first comprehensive threat assessments of generative language models for influence operations, grounded in both AI capabilities and real-world disinformation tactics. The ABC framework is useful for structuring threats, and the mitigation taxonomy is practical for policymakers. However, the paper is necessarily speculative—it describes future-oriented scenarios, and actual adoption and impact remain uncertain. The authors appropriately acknowledge their backgrounds (several authors work or have worked in AI industry) may bias their perspective. The paper has been influential in policy circles and informed subsequent research on LLM-generated disinformation and detection.
One limitation: the paper focuses on text and text-to-speech models, not multimodal generative models (text-to-image, deepfakes). The threat landscape for multimodal generation is similarly large but underexplored here.