The Looming Threat of Fake and LLM-generated LinkedIn Profiles: Challenges and Opportunities for Detection and Prevention¶
Authors: Navid Ayoobi, Sadat Shahriar, Arjun Mukherjee
Venue: 3rd ACM Conference on Hypertext and Social Media (HT '23), September 4-8, 2023, Rome, Italy — DOI
TL;DR¶
LinkedIn's lack of verification enables fake accounts that harm legitimate users and the platform's integrity. This work introduces a dataset of 3600 profiles (legitimate, manually created fake, and ChatGPT-generated) and proposes SSTE, a method that detects fake profiles immediately after registration using only profile text. The approach achieves 95% accuracy distinguishing legitimate from fake profiles and can identify LLM-generated profiles with ~70% accuracy despite not being trained on any LLM-generated content.
Contributions¶
- Large, publicly available dataset of 3600 LinkedIn profiles: 1800 legitimate profiles, 600 human-created fake profiles, and 1200 ChatGPT-generated profiles.
- Section and Subsection Tag Embedding (SSTE) method for detecting newly registered fake profiles using only textual data from profile sections, without requiring dynamic data (followers, connections, activity).
- First detector capable of discriminating between legitimate profiles, manually created fake profiles, and LLM-generated profiles.
- Demonstration that the method can identify LLM-generated profiles with reasonable accuracy despite not being exposed to LLM-generated content during training.
Method¶
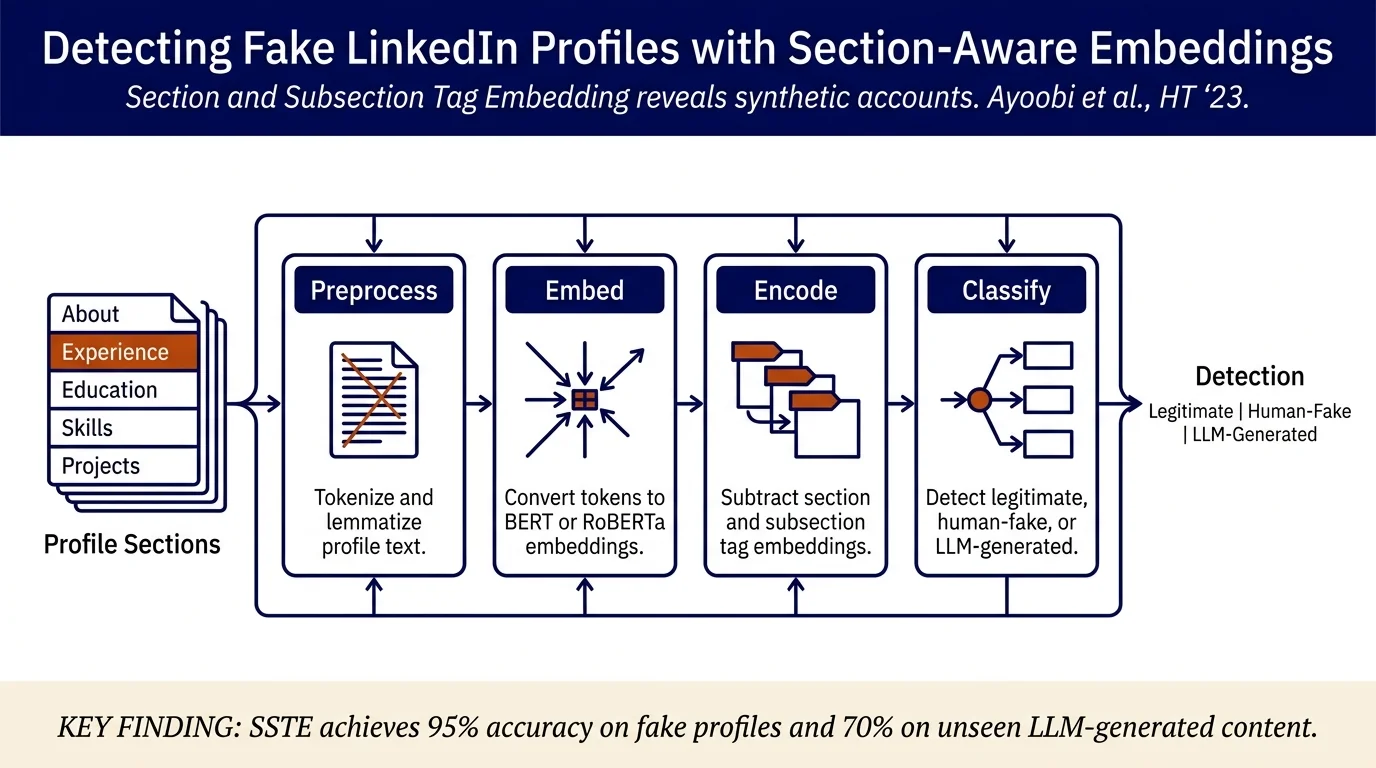
The key insight is that fake profiles, especially those created by LLMs, exhibit distinctive textual patterns. The SSTE method operates on LinkedIn profile text organized into sections (About, Experience, Education, Skills, etc.).
Preprocessing: Profile text is converted to lowercase, URLs and punctuation removed, and text is tokenized and lemmatized using NLTK.
Word embeddings: The method evaluates four embedding schemes: GloVe, Flair, BERT-base, and RoBERTa. These map tokens to numerical vectors.
Section and Subsection Tag Embedding (SSTE): Rather than treating all profile text equally, the method explicitly encodes which section/subsection each token originates from. For each token embedding, the mean embedding of section and subsection tags is subtracted. This operation isolates discriminative content by removing shared patterns and emphasizing section-specific distinctions. The final profile representation is the mean of all embedded tokens across sections.
Classification: A binary classifier (trained on legitimate profiles and human-created fake profiles) uses the embedded profile representation. For LLM detection, the same classifier is tested on unseen ChatGPT-generated profiles.
Results¶
Legitimate vs. fake detection: Using BERT embeddings with SSTE, the method achieves 95% accuracy and 0.950 F1-score on a test set of 180 legitimate profiles and 180 fake profiles. This outperforms a baseline (87.78% accuracy) that uses numerical features only. Section-tag embedding (STE, without subsection tags) has lower performance than SSTE, suggesting subsection-level distinctions matter.
LLM-generated profile detection: When trained on 600 legitimate profiles and 600 human-created fake profiles, the SSTE model achieves 70%+ accuracy identifying unseen ChatGPT-generated profiles, despite ChatGPT content being absent from training. This demonstrates generalization to next-generation fake profiles. With only 20 ChatGPT-generated profiles in the training set, accuracy reaches ~90%, suggesting the method is robust to proliferation of LLMs.
Section contribution analysis: The Experience section is most discriminative; removing it drops accuracy substantially. About, Education, and Skill sections also contribute meaningfully. This aligns with the observation that LLMs struggle most with fine-grained contextual writing (work history, duration, specific locations) and excel at generic summaries.
Comparison of embeddings: BERT and RoBERTa (contextual embeddings) consistently outperform GloVe (static embeddings). Contextual embeddings capture nuances better suited to distinguishing LLM-generated from human text.
Connections¶
- Related to Fake Account Detection as a LinkedIn-specific application.
- Shares dataset-creation methodology with FakeNewsNet (manual annotation of accounts).
- Relevant to Generative Model Detection and detection of LLM-generated content, distinct from prior work focused on LLM-generated text in written articles.
- Addresses challenges in Content authentication on social platforms where verification is weak.
- Builds on embeddings-based detection approaches, similar to sentiment analysis methods for fake accounts.
Notes¶
Strengths: The dataset is the first publicly available resource for LinkedIn fake profile detection at scale. The SSTE method is elegant and interpretable—subtracting section embeddings isolates discriminative content. The paper demonstrates both immediate applicability (detecting human-created fakes) and future relevance (detecting LLM-generated fakes before proliferation becomes critical).
Limitations: The method relies on textual profiles accessible immediately after registration, which may not capture all dynamic evasion tactics (gradual credibility building). The ChatGPT profiles are generated from profile statistics, not by actual attackers with tactical knowledge. The paper does not explore other LLMs (GPT-4, Claude, etc.), though the authors note this is vital as LLM diversity increases. The detection of hybrid profiles (partially LLM-generated) is unexplored.
Future work: The authors identify the need to detect partially LLM-assisted profiles and to understand how LLMs might be used to enhance credible portions of a fake profile rather than generate it wholesale.