Assessing the Quality of the Datasets by Identifying Mislabeled Samples¶
Authors: Vaibhav Pulastya, Gaurav Nuti, Yash Kumar Atri, Tanmoy Chakraborty Venue: arXiv, 2021 — arxiv:2109.05000
TL;DR¶
Deep learning models with high capacity often memorize label noise, degrading generalization. This paper proposes AQUAVS, a supervised variational autoencoder that identifies mislabeled samples via a "noise score" computed from outliers in latent space representations. The method requires no access to clean subsamples or prior knowledge of noise type, and achieves >94% accuracy on MNIST under various corruption levels.
Contributions¶
- A novel algorithm using latent space outlier detection to assign quality scores to samples and identify mislabeled data points.
- A method that operates without requiring clean validation data or prior knowledge about the type of noise in the dataset.
- Extensive experiments on MNIST, FashionMNIST, CIFAR-10, and CIFAR-100 under uniform and systematic label-corruption regimes, showing improvements over baseline methods.
Method¶
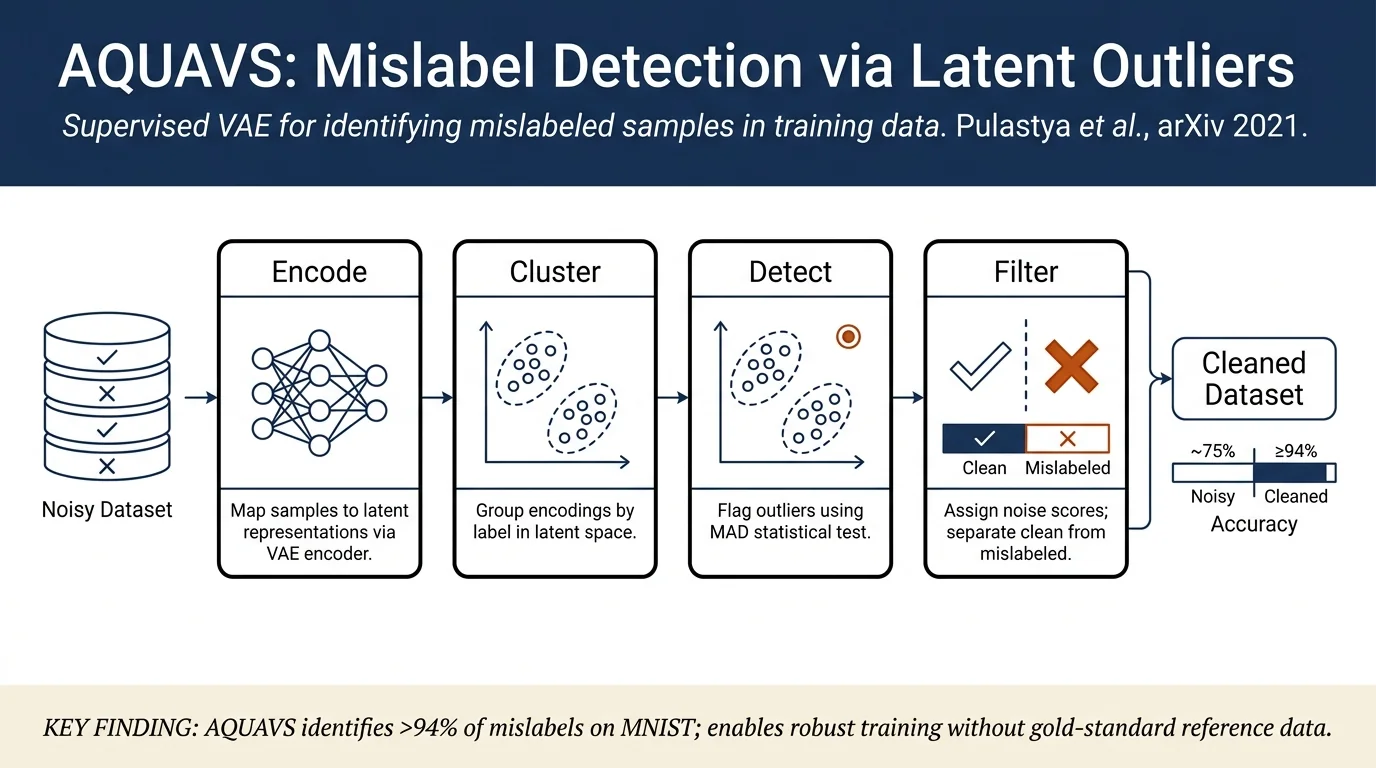
AQUAVS architecture: Extends standard VAEs with an auxiliary discriminative network to jointly learn latent representations and label predictions. For an input \(x\), the model learns \(p(x, z, y) = p(z)p(x|z)p(y|z)\), where \(z\) is the latent variable and \(y\) is the predicted label.
Training objective: Combines ELBO loss (reconstruction + KL regularization) with categorical cross-entropy classification loss: $\(L = L_{\text{ELBO}} + L_{\text{cl}}\)$
Noise score computation: Assuming samples of the same class cluster in latent space, the noise score for each sample is the count of outlying latent features using median absolute deviation (MAD) with hyperparameter \(\alpha=1.5\). Algorithm 1 groups the dataset by label, computes the median and MAD of latent encodings per class, then counts how many dimensions exceed \(m_j + \alpha M_j\) for each sample.
Results¶
Mislabel identification¶
On MNIST with uniform noise up to 40%, AQUAVS achieves precision, recall, and accuracy consistently ≥0.94. Systematic noise (e.g., digit 8 mislabeled as 3) is harder to detect; performance drops more significantly on CIFAR-100 with high noise due to dataset complexity. Outperforms LabelFix and entropy-based training dynamics baselines on systematic noise tasks.
Robust training¶
After filtering identified mislabeled samples, classification models trained on the cleaned subset show significant improvements. On MNIST with 10–20% uniform noise, AQUAVS-filtered training even exceeds oracle (clean-only) performance, suggesting the method identifies both incorrect labels and "hard" but correct samples. CIFAR-100 shows marginal gains, indicating label quality matters less when data quantity is sufficient for complex tasks.
Connections¶
- Related to Label noise in noisy-label learning; extends prior work on training dynamics and sample importance weighting.
- Complements Data quality assessment; critical for practitioners curating high-stakes datasets.
- Uses VAE architecture with supervised extensions, similar to semi-supervised learning frameworks.
Notes¶
Strengths: - Clear motivation: label noise is ubiquitous in web-scraped and crowdsourced datasets. - No reliance on clean subsets or noise-type priors—practical for real-world scenarios. - Comprehensive evaluation across datasets and noise models.
Limitations: - Noise score based on MAD is univariate and may miss multivariate outliers. - Performance degrades sharply on high-noise, high-complexity datasets (CIFAR-100 at 40% noise). - No comparison with recent meta-learning or sample-weighting methods (e.g., AUM, which uses training margins). - Assumes label noise is the only source of error; ignores feature noise or class imbalance.
For misinformation research: Dataset quality is foundational. If a fake-news detector is trained on noisily labeled news articles, it will memorize annotation errors. This method offers a practical way to identify and remove mislabeled examples before training, improving robustness and generalization.