Perceived and Intended Sarcasm Detection with Graph Attention Networks¶
Authors: Joan Plepi, Lucie Flek Venue: arXiv, 2021 — arXiv:2110.04001
TL;DR¶
Sarcasm detection requires understanding both the author's intent and the audience's perception. This work proposes a graph attention network (GAT) that jointly models user historical context and conversational social network information on Twitter, achieving state-of-the-art results on the SPIRS dataset and showing that detecting sarcastic intentions is easier than predicting how others perceive sarcasm.
Contributions¶
- First graph attention-based model for sarcasm detection that explicitly models users' social and historical context jointly, capturing complex relations between sarcastic tweets and their conversational context
- Demonstration that exploiting user and social relationships improves sarcasm detection performance on the SPIRS dataset (19k Twitter users, 30k labeled tweets plus 10M unlabeled historical tweets as context)
- Finding that even with user-based models, detecting the author's sarcastic intentions is more reliable than identifying sarcasm perception by others, suggesting different features drive these two subtasks
Method¶
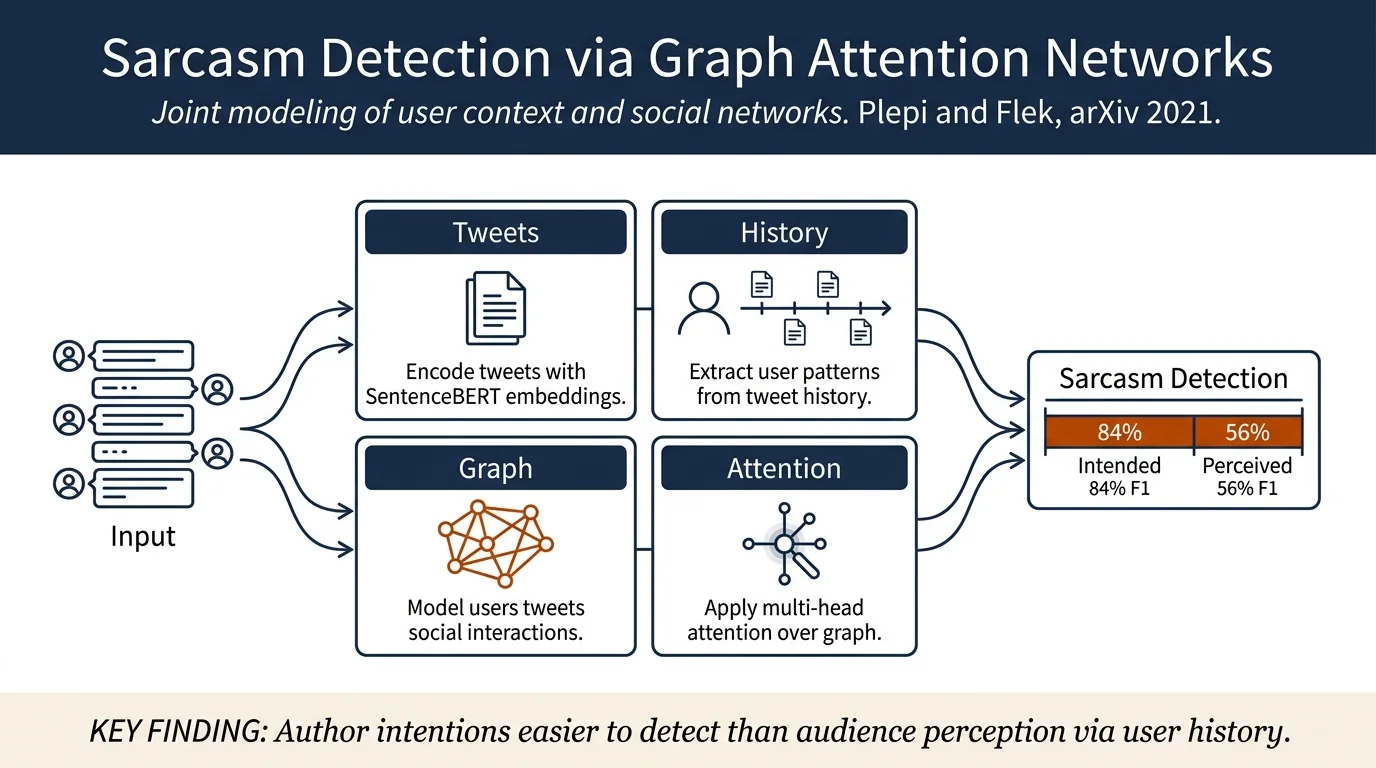
The framework combines three components:
Tweet Embeddings: SentenceBERT (mean pooling over token representations) encodes tweets into 768-dimensional vectors, then linearly projects to dimension \(d\).
User Embeddings (Historical Context): user2vec computes user representations from their historical tweets by optimizing the conditional probability of texts given the author, capturing behavioral patterns and sentiment tendencies.
Social Graph (Network Context): A heterogeneous graph \(G = (V, E)\) models users and tweets as nodes with three edge types: - \(e^U\): social interactions (quotes, mentions, replies) between users - \(e^T\): all-to-all connections between tweets in a conversation thread - \(e^C\): relations between tweets and their authors
Graph Attention Networks initialize nodes with user2vec and tweet embeddings, then apply multi-head self-attention over the neighborhood of each node to compute final representations. The attention mechanism assigns importance scores to relationships contributing to sarcasm detection. Final node representations aggregate information from multiple attention heads via mean pooling, then concatenate user and tweet representations and pass through a two-layer feedforward classification network.
Results¶
On the SPIRS dataset without cue tweets (most realistic setting):
- User+tweet GAT (no cues): 84.2% F1 — significantly outperforms BERT (69.9%), BERT + user2vec (73.4%), and tweet-tweet only GAT (70.1%)
- BERT + user-only GAT: 76.1% F1 — 6.1% improvement from social graph alone
- Adding oblivious/elicit tweets gives 2-3% drops; adding cue tweets (oracle setting) reaches 94.5% F1
For perceived vs. self-reported sarcasm: - Self-reported (intended) sarcasm: F1 84% — user history more informative - Perceived sarcasm: F1 56% — harder task; user-based models less helpful
Attention analysis shows the model weights user nodes and classified tweets most heavily; conversational context (oblivious/elicit edges) only becomes decisive when user-level priors are weak.
Connections¶
- Related to Graph Neural Networks for modeling social and structural relationships
- Extends prior work on User Context in Sarcasm Detection (Amir et al. 2016, Oprea and Magdy 2019)
- Complements Sentiment Analysis and Stance Detection as related NLP tasks affected by sarcasm
- Relevant to Social Media Analysis for leveraging network structure in Twitter understanding
- Similar approach to Fake news detection using graph and social context (Chandra et al. 2020)
Notes¶
This is a well-motivated application of graph attention networks to sarcasm detection, addressing a genuine linguistic and social phenomenon: sarcasm interpretation depends critically on author context and audience relationship. The distinction between perceived and intended sarcasm is important and often overlooked; the finding that user history helps more for intended sarcasm suggests these are indeed different problems.
Strengths: The heterogeneous graph design (users, tweets, and their interactions) is sensible. Adding 10M tweets as historical context moves beyond surface-level features. The ablations are thorough (removing elicit/oblivious tweets, analyzing attention weights).
Limitations: The augmented SPIRS dataset introduces selection bias—coverage is only as broad as the initial annotations. Graph density is low (0.00002) and homophily weak (32%), limiting the graph's signal. The approach still struggles with perceived sarcasm, likely because modeling recipient profiles is harder than author profiles. Ethical considerations around stereotyping users as "sarcastic" are noted but not fully resolved.
Follow-up directions: Modeling recipient context alongside author context could improve perceived sarcasm detection. Testing on other social platforms or languages would validate generalization.