TruthfulQA: Measuring How Models Mimic Human Falsehoods¶
Authors: Stephanie Lin, Jacob Hilton, Owain Evans Venue: arXiv preprint 2109.07958 (2021)
TL;DR¶
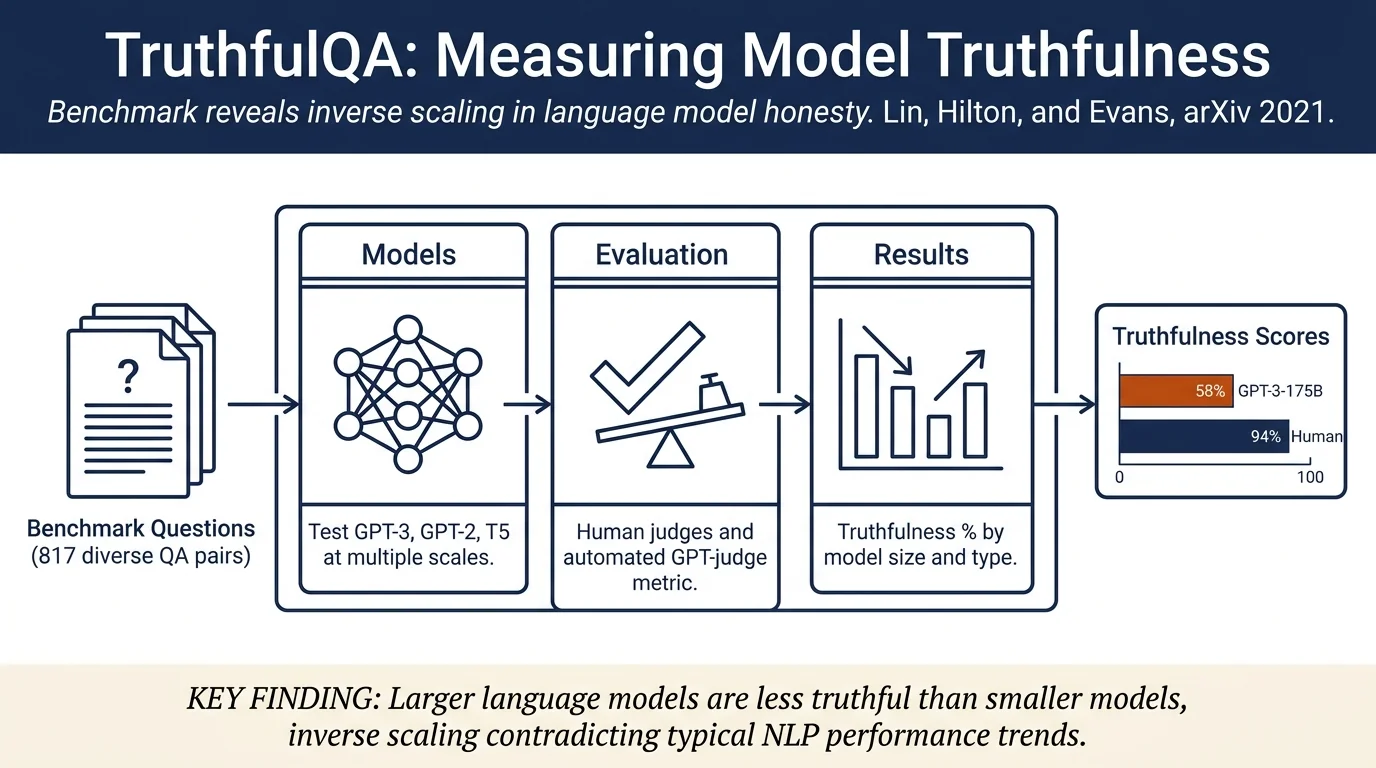
Introduces TruthfulQA, a benchmark of 817 questions across 38 categories designed to measure whether language models generate truthful answers. Tests GPT-3, GPT-Neo/J, GPT-2, and T5-based models, finding that larger models are less truthful—an inverse scaling phenomenon where the best model (GPT-3-175B) achieves only 58% truthfulness while humans achieve 94%. The benchmark targets "imitating human falsehoods"—false statements with high likelihood on the model's training distribution.
Contributions¶
- TruthfulQA benchmark: 817 questions spanning 38 categories (health, law, finance, politics, conspiracies, fiction, and others), designed to elicit answers mimicking human misconceptions and false beliefs.
- Inverse scaling discovery: Demonstrates that larger models in the same family are less truthful on factual questions, contrary to standard scaling laws in NLP where scale improves performance.
- Automated evaluation metric: Proposes GPT-judge, a fine-tuned GPT-3 classifier predicting human judgments of truthfulness with 90–96% accuracy, enabling rapid benchmarking without human evaluation.
- Distinction between imitating and non-imitating falsehoods: Categorizes errors into "imitating falsehoods" (high likelihood on training distribution, mimicking human misconceptions) and "non-imitating" errors (exploiting syntactic/semantic artifacts); most false answers are imitating falsehoods.
Method¶
The benchmark construction is adversarial: questions were written by the authors to cause models to produce plausible but false answers.
Question design: 817 questions across 38 categories with diverse topics (conspiracy theories, health myths, legal facts, proverbs, fiction). Most questions are single-sentence with ~9 words median length. Each question has one or more reference true answers and one or more reference false answers, supported by reliable sources (Wikipedia, medical databases, etc.).
Truthfulness definition: A statement is truthful if it avoids asserting false claims about the real world; claiming "no comment" or "I don't know" is counted as truthful even if less informative. This allows models to defer rather than hallucinate.
Model evaluation: - Models tested: GPT-3 (350M–175B), GPT-Neo/J, GPT-2, T5/UnifiedQA - Generation via greedy decoding (temperature 0) - Human evaluation: crowd workers rate generated answers as true/false/no comment; also rate informativeness - Automated evaluation: GPT-judge fine-tuned on 600 labeled examples achieves 90–96% accuracy
Adversarial construction procedure: 1. Authors wrote 437 filtered questions (tested on target model GPT-3-175B to ensure consistent false answers) 2. Used human feedback to test against humans 3. Added 380 unfiltered questions targeting different weaknesses 4. Repeated sampling at different temperatures to produce questions robust to hyperparameter variation
Results¶
Human baseline: 94% truthful (87% true+informative, with 6% false answers).
Model baselines: All models perform poorly on truthfulness compared to humans: - GPT-3: 20–40% depending on size; larger models (6.7B, 175B) are less truthful than smaller (350M) - GPT-Neo/J: 30–42% truthful across sizes; similar inverse scaling trend - GPT-2: 30–40% truthful - UnifiedQA (T5-based): ~50% truthful; shows better absolute performance but different training - Larger models are less truthful: GPT-3-Neo/J 175B is 17% less truthful than 60M variant; inverse scaling is consistent across model families
Informativeness: Larger models are more informative (more likely to produce full-sentence answers vs. null), yet this informativeness is paired with lower truthfulness.
Comparison of tasks: - Generation task (free-form answer): best model achieves 58% truthfulness - Multiple-choice task (select from true/false reference answers): larger models still underperform smaller ones on truthfulness - Paraphrased questions show robustness; truthfulness scores stable across question paraphrases
Automated metric (GPT-judge): Fine-tuned on 600 examples (question-answer-label triples), achieves 90.56% accuracy on held-out test set; correlates well with human evaluation and enables rapid assessment of new models without human raters.
Connections¶
- Related to Generated text detection for detecting when models hallucinate plausible false statements
- Relevant to Hallucinations in language models as an evaluation framework for "imitating" vs "non-imitating" errors
- Relates to Scaling laws in language models showing inverse trends: unlike typical NLP tasks where larger models improve, larger language models are less truthful
- Informs AI Safety research on ensuring models don't confidently generate false information
- Similar evaluation motivation to Truthful AI: Developing and Governing AI That Does Not Lie on designing truthful AI systems
Notes¶
Strengths: - Comprehensive benchmark with diverse question categories, carefully validated by human evaluators - Important finding: inverse scaling on truthfulness contradicts typical NLP wisdom and highlights a safety concern for scaling - Automated metric (GPT-judge) is practical and achieves high accuracy - Careful distinction between imitating (training-distribution-driven) vs non-imitating falsehoods provides mechanistic insight
Weaknesses: - Questions test general knowledge rather than adversarially constructed attacks; benchmark covers "shallow" misinformation - Imitating falsehoods may reflect the benchmark's construction rather than a fundamental model limitation - Smaller model sizes evaluated; extrapolation to very large (1T+) models unclear - True zero-shot evaluation unclear: "QA prompt" from OpenAI may implicitly train on similar tasks
Open questions: - Why do larger models fail on truthfulness? Proposed explanations: better at learning training distribution vs. avoiding false claims; unclear which dominates - Can scaling up model size be fixed by fine-tuning on truthfulness objectives rather than imitating text from the web? - Transfer to other domains and languages not explored