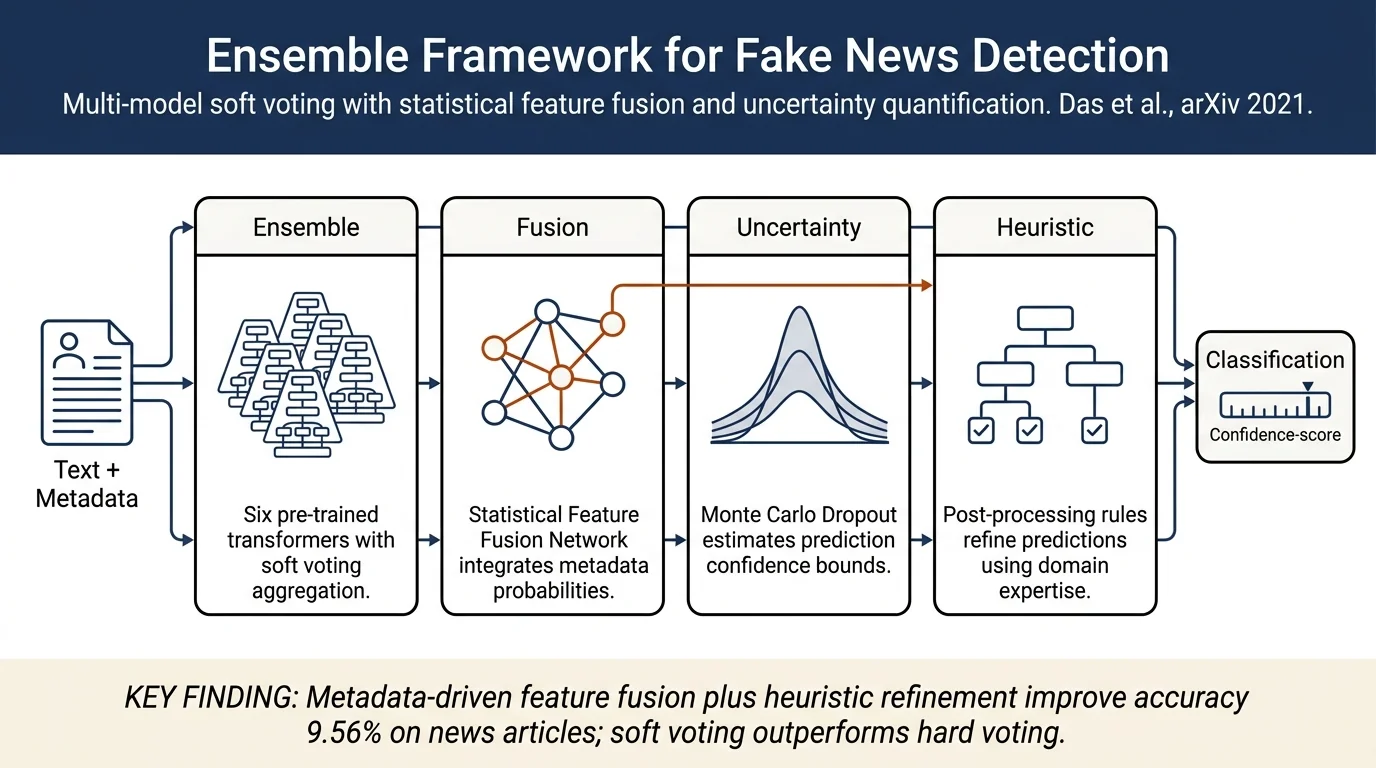
A Heuristic-driven Uncertainty based Ensemble Framework for Fake News Detection in Tweets and News Articles¶
Authors: Sourya Dipta Das, Ayan Basak, Saikat Dutta
Affiliations: Razorthink Inc. (USA), IIT Madras (India)
arxiv: 2104.01791
TL;DR¶
An ensemble-based fake news detection system combining multiple pre-trained language models (BERT, RoBERTa, XLNet, DeBERTa, ERNIE 2.0, ELECTRA) with a Statistical Feature Fusion Network (SFFN) and heuristic post-processing. The framework incorporates Monte Carlo Dropout for uncertainty estimation and leverages metadata features (URL domains, usernames, news sources, authors) to boost performance. Achieves F1-score of 0.9892 on COVID-19 Fake News and 0.9156 on FakeNewsNet datasets.
Contributions¶
- Ensemble architecture combining pre-trained language models with soft voting to leverage complementary knowledge from different transformers
- Statistical Feature Fusion Network (SFFN) that integrates conditional probability features derived from metadata attributes (username handles, URL domains, news sources, authors) to create a unified feature space
- Uncertainty estimation framework using Monte Carlo Dropout to quantify prediction confidence alongside classification outputs, improving system reliability
- Heuristic post-processing algorithm that applies domain-specific rules based on statistical features to refine ensemble predictions, capturing cases where metadata is a strong predictor
- Comprehensive evaluation on both social media (tweets) and long-form news articles, demonstrating cross-domain applicability
Method¶
The framework consists of seven main components:
Text preprocessing — For tweets, filter out usernames, URLs, and emojis using tweet-preprocessor library. For news articles, remove mentions and URLs from social media platforms. This ensures clean text input to language models.
Tokenization — Use multiple tokenizers corresponding to the backbone models (BERT, XLNet, RoBERTa, XLM-RoBERTa, DeBERTa, ELECTRA, ERNIE 2.0), each with their associated vocabularies and special tokens.
Backbone model architectures — Fine-tune seven pre-trained transformer models by adding a fully-connected layer to each encoder's output for binary classification. Use transfer learning with frozen pre-trained weights, then fine-tune on the target dataset using cross-entropy loss and AdamW optimizer. Maximum sequence length set to 128 tokens; initial learning rate 2e-5.
Ensemble with soft voting — Compute prediction probabilities for "real" and "fake" classes from each fine-tuned model. Calculate average probability across models: $\(P^r(x) = \frac{1}{n}\sum_{i=1}^{n} P_i^r(x), \quad P^f(x) = \frac{1}{n}\sum_{i=1}^{n} P_i^f(x)\)$ Soft voting captures complementary strengths of individual models and outperforms hard voting (majority vote).
Statistical Feature Fusion Network (SFFN) — Extract metadata features for tweets (username handles, URL domains) and news articles (news sources, authors). Calculate conditional probabilities indicating whether each feature value predicts "real" or "fake": $\(P^r(x|\text{attribute}_k) = \frac{n(A)}{n(A) + n(B)}\)$ where \(n(A)\) = count of "real" items with the attribute value, \(n(B)\) = count of "fake" items. Append these probability vectors to ensemble predictions, then pass through a neural network with Monte Carlo Dropout (applied at inference time) to produce final predictions with uncertainty estimates.
Uncertainty estimation — Apply Monte Carlo Dropout with multiple stochastic forward passes during inference. For \(N\) samples with different dropout masks, compute mean and variance: $\(v_p = \mu_s = \frac{1}{N}\sum_{i=0}^{N} f_{SFFN}^{d_i}(x), \quad c_u = \sigma_s^2 = \frac{1}{N}\sum_{i=0}^{N}[f_{SFFN}^{d_i}(x) - v_p]^2\)$ Mean represents point estimate; variance indicates prediction confidence. Thresholds chosen via elbow method (0.88 for COVID-19, 0.94 for FakeNewsNet).
Heuristic post-processing — After ensemble prediction, apply rule-based refinements leveraging statistical features. Core intuition: if a single feature (e.g., URL domain or author) strongly indicates fake, reassign label accordingly. Algorithm checks attribute probabilities and may override ensemble output based on thresholds, allowing manual incorporation of domain expertise.
Results¶
On the COVID-19 Fake News dataset (10,700 tweets/articles, 47.66% fake): - Best soft-voting ensemble (RoBERTa + XLM-RoBERTa + XLNet + ERNIE 2.0 + Electra): F1 = 0.9908, Accuracy = 0.9908 - With SFFN and heuristic post-processing: F1 = 0.9892, Accuracy = 0.9804 - Individual models (XLM-RoBERTa, RoBERTa, XLNet, ERNIE 2.0): F1 ≈ 0.966–0.976
On the FakeNewsNet dataset (16,817 news items, 75% real): - Best soft-voting ensemble (RoBERTa + XLM-RoBERTa + XLNet + DeBERTa + NewsERT): F1 = 0.8718, Accuracy = 0.8718 - With SFFN and heuristic post-processing: F1 = 0.9156, Accuracy = 0.9101
Key findings: - Soft voting ensembles consistently outperform individual models on both datasets - Hard voting ensembles show lower performance due to class imbalance in decision aggregation - SFFN with heuristic post-processing provides significant boost (9.56% improvement in accuracy on FakeNewsNet) - Statistical features from metadata are crucial for long-form news articles, less so for tweets - Uncertainty estimates via Monte Carlo Dropout are well-calibrated, enabling selective prediction and active learning scenarios
Connections¶
- Related to Ensemble Methods by demonstrating complementarity of different transformer architectures in classification tasks
- Extends Fake news detection methods with a unified framework handling both tweets and articles
- Contributes to Neural networks and Language Models literature by showing transfer learning effectiveness across multiple pre-trained models
- Employs Uncertainty estimation techniques (Monte Carlo Dropout) for reliable confidence estimation in critical classification tasks
- Uses Deep learning for automated feature extraction and fusion from text and metadata
- Related to Statistical feature engineering by leveraging URL domains, usernames, and source attributes
- Builds on COVID-19 misinformation and the infodemic research by addressing pandemic-related fake news detection
- Cited challenges similar to FakeNewsNet work on multi-domain news credibility assessment
Notes¶
Strengths: - Well-motivated combination of pre-trained transformers (BERT, RoBERTa, XLNet, DeBERTa, ERNIE 2.0, ELECTRA) capturing complementary linguistic representations - Practical framework handling both social media and news articles without separate pipelines - Uncertainty quantification via MC Dropout provides actionable confidence scores, not just class predictions; improves interpretability and enables active learning - Comprehensive ablation studies (Tables 5–16) showing contribution of ensemble vs. SFFN vs. heuristic post-processing components - Heuristic rules are domain-interpretable and allow incorporation of human expertise without end-to-end retraining - Statistical features derived from training data frequencies, making the approach data-driven despite rule-based post-processing - Significant absolute improvements on FakeNewsNet (+9.56% accuracy) demonstrate practical utility
Weaknesses: - Heuristic post-processing thresholds (0.88, 0.94) chosen via elbow method; sensitivity analysis and generalization to new domains unclear - Limited theoretical justification for why MC Dropout is suitable for uncertainty; other Bayesian approximations (e.g., ensemble variance) not compared - Statistical Feature Fusion Network trains on training set statistics; may overfit attribute probabilities to training distribution, harming generalization to new sources/users - Cross-domain robustness not tested: models trained on COVID-19 data evaluated on COVID-19; unknown how transferable to other rumor domains - Class imbalance handling via KMeans-SMOTE not fully ablated; unclear contribution vs. SFFN and heuristic components - No comparison to recent graph-based or propagation-aware methods; baseline comparisons focus on classical ML (Logistic Regression, SVM, Decision Tree) - Paper submitted to Neurocomputing (December 2021); unclear if published or under review
Follow-ups: - Compare MC Dropout uncertainty with ensemble variance and Bayesian neural networks on confidence calibration metrics - Test cross-domain transfer: train on COVID-19, evaluate on other rumor datasets (FakeNews-19, FEVER, etc.) to assess heuristic robustness - Analyze which statistical features are most informative per domain; develop adaptive threshold selection - Investigate multimodal extensions incorporating image and video features from social media - Conduct adversarial robustness analysis: can URL/username spoofing evade the heuristic post-processing?