Causal Understanding of Fake News Dissemination on Social Media¶
Authors: Lu Cheng, Ruocheng Guo, Kai Shu, Huan Liu Venue: ACM SIGKDD Conference on Knowledge Discovery and Data Mining, August 2021 — DOI
TL;DR¶
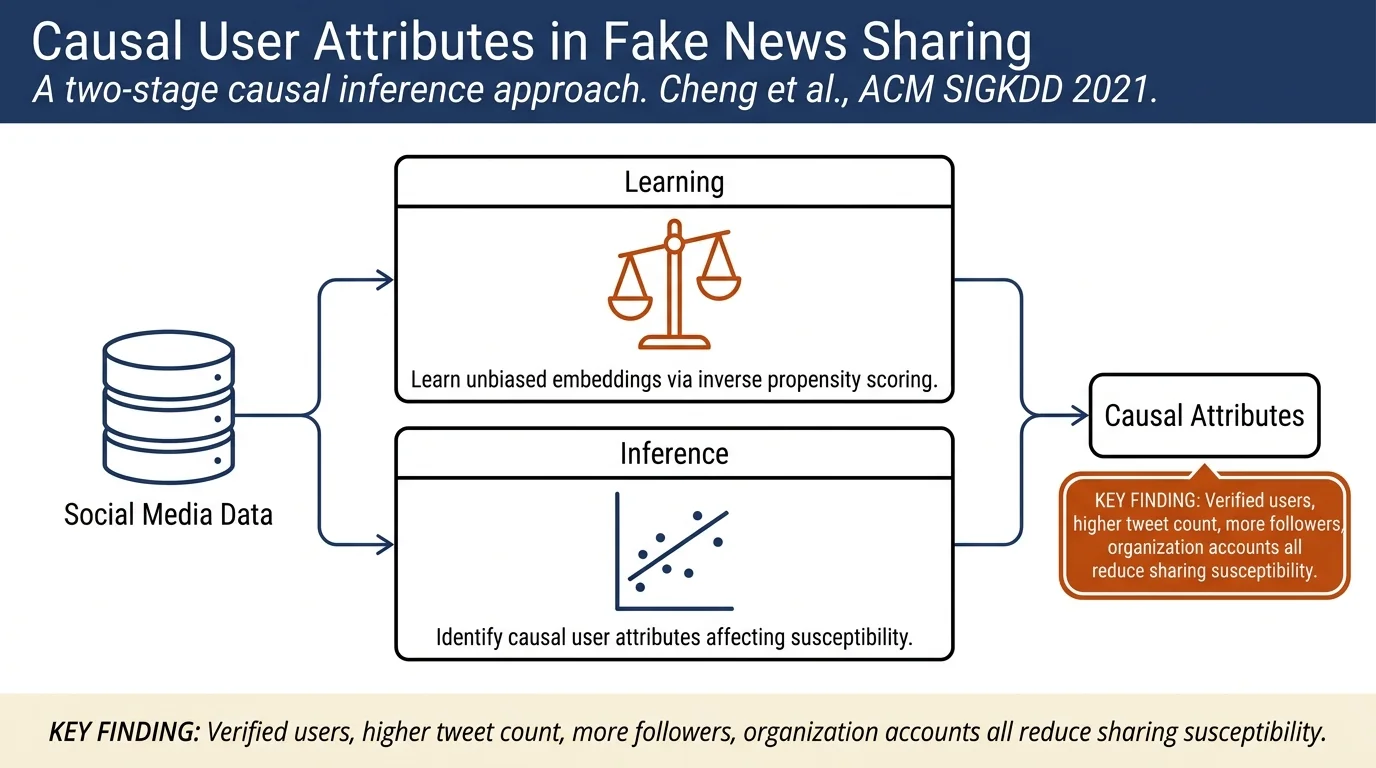
The paper addresses the fundamental causal question: what user attributes cause susceptibility to share fake news? Rather than observing correlations, the authors use inverse propensity scoring (IPS) to learn unbiased embeddings of fake news sharing behavior, treating these embeddings as confounders in a causal model. On PolitiFact and GossipCop, they identify attributes like verification status, tweet count, and follower count as significantly related to sharing susceptibility.
Contributions¶
- A novel causal inference framework for understanding fake news dissemination, shifting focus from detection to why people spread it.
- Three propensity score estimators (news-based, user-news-based, neural-network-based) to combat selection bias in observational social media data.
- Empirical evidence that unbiased embeddings of fake news sharing behavior improve prediction of user susceptibility and identify causal user attributes.
- Behavioral analysis showing users who share fake news exhibit more homogeneous sharing patterns than true-news sharers.
Method¶
The framework operates in two stages:
Learning Unbiased Sharing Behavior (Stage 1): Social media data suffers from selection bias—users see news based on platform recommendations and self-selection. The authors model fake news dissemination as a function of both user exposure and interest, then apply IPS to reweight observed interactions. The propensity score θ_{ui} = P(exposure | interest) accounts for the fact that a user's lack of observed sharing may reflect non-exposure rather than disinterest. Three variants estimate propensity: news popularity alone, combined with user follower counts, or learned jointly via neural network. A non-negative loss variant reduces variance in the reweighting.
Identifying Causal User Attributes (Stage 2): With unbiased user embeddings in hand, the authors use a causal regression model: B_u = β^T a_u + γ^T U_u, where B_u is user susceptibility, a_u are user attributes (age, gender, verification status, etc.), and U_u are the learned embeddings acting as a confounder. This follows standard causal assumptions (SUTVA, positivity, conditional independence). Coefficients in β reveal which attributes are causally associated with susceptibility.
Results¶
On PolitiFact (624 real, 432 fake news; 110K users) and GossipCop (16.8K real, 5.3K fake; 194K users):
Predictive accuracy: IPS-reweighted models outperform baselines. On PolitiFact with BPRMF, Recall@20 improves by 20.6% (12.36 → 14.90) with neural-network-based propensity. Similar gains on GossipCop with both BPRMF and NCF baselines.
Sharing behavior differences: Fake news sharing behavior clusters tightly (silhouette coefficient −0.124), while true news sharing disperses widely (0.903), suggesting users who share fake news exhibit more homogeneous behavior.
Causal attributes: In both datasets, verified users, users with more tweets, users with more friends, and organization accounts show negative effects on susceptibility—they are less likely to share fake news. Conversely, #favorites and #followers show inconsistent effects across datasets, suggesting they are less causally stable. Gender, age, and registration time show nearly zero effects, aligning with prior psychological surveys.
Connections¶
- Related to understanding user profiles and characterizing user vulnerability.
- Extends propagation-based detection by asking not whether a cascade looks fake, but what user attributes precede fake sharing.
- Applies causal inference methods (inverse propensity scoring) familiar in recommender systems and domain adaptation to the fake news domain.
- Empirically validates psychology findings on self-presentation and social comparison as drivers of fake news spread.
- Differs from detection-focused work by centering user behavior and causal mechanisms rather than news content or network structure.
Notes¶
Strengths: The paper brings rigorous causal inference to a social science question, clearly articulates the selection bias problem in observational social media data, and provides multiple practical propensity estimators. The behavioral comparison (fake vs. true news sharing) yields an interesting empirical finding. The framework is transparent and reproducible (code released).
Limitations: The work relies on Twitter data only; results may not transfer to other platforms (TikTok, Facebook, etc.). User susceptibility is approximated as a share of fake news in a user's history, which conflates gullibility and malice. The causal assumptions (conditional independence given embeddings, SUTVA) may be violated by unmeasured confounders (e.g., news source category, cultural norms) and inter-user dependencies. Ground truth causal attributes are unavailable, limiting validation. As the authors acknowledge, observational data cannot conclusively identify causation—the "potentially causal" framing is appropriate.
Follow-ups: Interdisciplinary collaboration to obtain ground-truth causal attributes via survey or experiment. Analysis of other social media platforms. Deeper exploration of news content and user social networks as additional confounders. Temporal dynamics—how do attributes predict future sharing?