A General Language Assistant as a Laboratory for Alignment¶
Authors: Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DaSarma, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Jackson Kernion, Kamal Ndousse, Catherine Olsson, Dario Amodei, Tom Brown, Jack Clark, Sam McCandlish, Chris Olah, Jared Kaplan
Affiliation: Anthropic
Posted: 2021
TL;DR¶
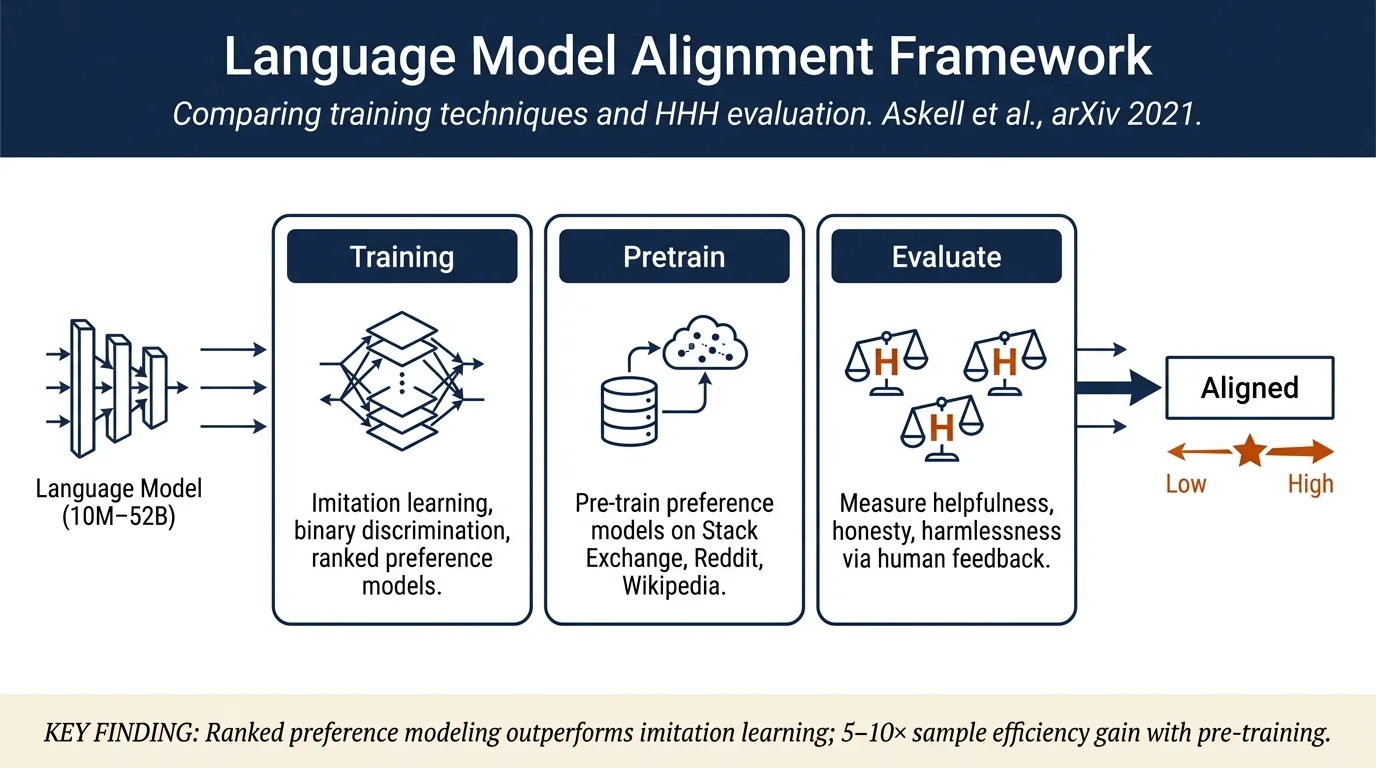
Anthropic builds an interactive evaluation framework for measuring large language model alignment using three criteria: helpfulness, honesty, and harmlessness (HHH). By comparing prompting, imitation learning, binary discrimination, and ranked preference modeling approaches, the authors find that ranked preference models scale better than imitation learning and can be pre-trained on public data to improve sample efficiency in alignment training.
Contributions¶
- Framework for evaluating AI alignment on diverse natural language tasks with human feedback collection interface
- Comparison of alignment techniques (prompting, context distillation, imitation learning, binary discrimination, ranked preference modeling) across varying model scales (10M–52B parameters)
- Finding that ranked preference modeling improves significantly over imitation learning and scales more favorably with model size
- Introduction of preference model pre-training (PMP) on public data (Stack Exchange, Reddit, Wikipedia) to improve sample efficiency
- Measurement of alignment properties through HHH evaluation, toxicity detection, and head-to-head human preference comparisons
- Analysis of alignment tax/bonuses: demonstration that prompts reduce toxicity without significantly harming performance on other tasks
Method¶
The work studies alignment through training and evaluation on language models ranging from 10M to 52B non-embedding parameters. Key techniques include:
Alignment Approaches: - Prompting: Including an instruction prompt (e.g., "You should be helpful, harmless, and honest") as context - Context Distillation: Finetuning models to match the distribution of the original model conditioned on a prompt - Imitation Learning: Training on human-written examples of good behavior via supervised learning - Binary Discrimination: Training to distinguish between correct and incorrect behavior in a pass/fail framework - Ranked Preference Modeling: Training models to rank possible outputs by quality, leveraging hierarchical preference information
Evaluation Framework: Authors develop an interactive interface for A/B testing models and collecting fine-grained human feedback on helpfulness, honesty, and harmlessness. They define HHH criteria: - Helpful: The AI makes a clear attempt to perform the task or answer the question - Honest: The AI provides accurate information and calibrates confidence appropriately - Harmless: The AI avoids offensive or discriminatory behavior and recognizes harmful requests
Preference Model Pre-training (PMP): A two-stage training pipeline: (1) pre-train preference models on large public datasets, then (2) finetune on smaller human-feedback datasets. This improves sample efficiency while maintaining performance.
Results¶
Scaling: Ranked preference modeling consistently outperforms imitation learning as model scale increases, with accuracy gains of 13–21% on HHH evaluations. Binary discrimination provides minimal benefit over imitation learning.
Preference Model Pre-training: PMP significantly improves sample efficiency; models pre-trained on Stack Exchange, Reddit, and Wikipedia require 5–10× fewer finetuning examples to match supervised-learning baselines.
Alignment Taxes: Simple prompting reduces toxicity (measured via automated toxicity detectors) without meaningfully degrading performance on code, natural language, or ethics tasks. Larger models show smaller or no alignment tax.
Human Preferences: Head-to-head evaluations show Elo-score scaling roughly linear with log model size, with the HHH prompt showing slight preference over shorter prompts (Elo difference ~64 points at 52B parameters).
Cross-Task Transfer: Transfer learning with PMP works even when pre-training and finetuning datasets differ substantially (e.g., StackExchange pre-training transfers to summarization finetuning).
Connections¶
- Related to Kaplan et al.'s work on scaling laws for language model performance and sample efficiency
- Builds on preference learning and reinforcement learning from human feedback (RLHF) frameworks
- Connects to honesty and truthfulness research via TruthfulQA and HumanEval benchmarks
- Relevant to misinformation contexts: honest and harmless AI systems are critical for preventing AI-generated disinformation
Notes¶
This is a foundational paper on alignment evaluation and provides methodological contributions (the HHH evaluation framework and interactive A/B testing interface) that will be widely adopted. The finding that ranked preference modeling scales better than imitation learning is particularly important for practical alignment work. The paper's emphasis on measuring alignment across multiple dimensions (not just helpfulness) anticipates future work on multi-objective AI training. The role of model scale in alignment—both in whether models benefit from prompting and in whether alignment imposes performance costs—is underexplored but important. One limitation is reliance on automated toxicity detection for some evaluations, which the authors acknowledge has known biases.