Detection of Novel Social Bots by Ensembles of Specialized Classifiers¶
Authors: Mohsen Sayyadiharikandeh, Onur Varol, Kai-Cheng Yang, Alessandro Flammini, Filippo Menczer
Venue: arXiv, 2020 — arxiv:2006.06867
TL;DR¶
Different types of social bots exhibit heterogeneous behavioral features; training a single classifier on all bots fails to generalize to novel bot types. The authors propose ESC (Ensemble of Specialized Classifiers), which trains separate classifiers for each bot class and combines their decisions via a maximum rule, achieving a 56% improvement in F1 score on unseen bot types while maintaining in-domain accuracy and enabling efficient adaptation to new domains.
Contributions¶
- Empirical demonstration that cross-domain bot detection performance deteriorates due to heterogeneous bot behaviors requiring different feature sets.
- ESC method: a modular ensemble architecture where each specialized classifier RF_i targets a specific bot class, combined through a voting scheme that applies the maximum rule over specialized bot classifiers while inverting the human classifier score.
- Evidence that ESC identifies mislabeled accounts in training data more robustly than monolithic classifiers.
- Model adaptation efficiency: new bot classes can be added to the ensemble with fewer labeled examples, avoiding expensive retraining of the entire classifier.
- Deployment in Botometer v4 with cross-validation AUC of 0.99, serving over 500k queries daily.
Method¶
The paper identifies two key empirical findings: (1) human accounts are homogeneous across datasets, while bots are heterogeneous, and (2) different bot classes (traditional spambots, social spambots, fake followers) are distinguished by different feature subsets (adjective frequency, sentiment, friend-follower ratio respectively).
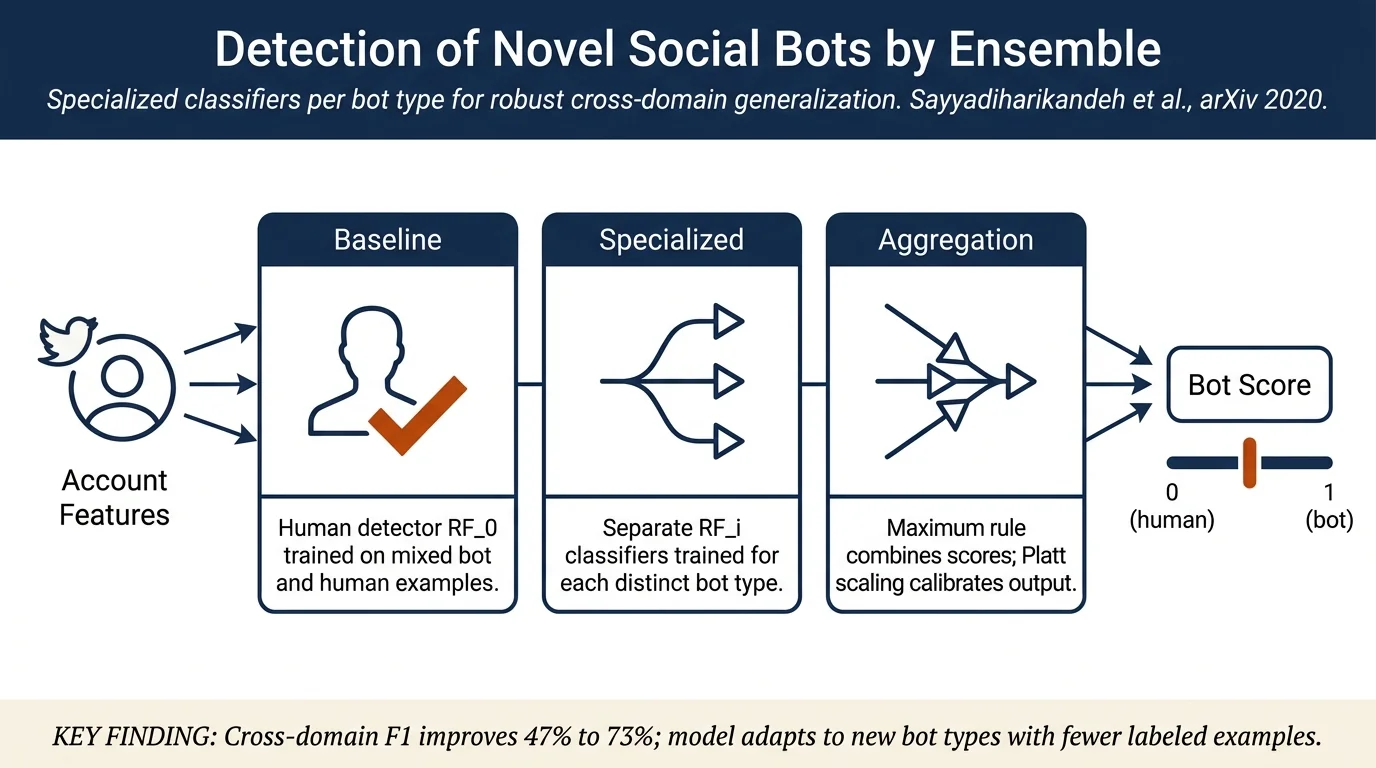
ESC architecture: RF_0 is a baseline human detector trained on all human and bot examples. RF_1 ... RF_n are specialized classifiers, each trained on a balanced set of examples from one bot class BC_i and an equal number of human examples. A test account receives scores from all classifiers. The final bot score is computed as s'* = max_i{s'_i}, where s'_i = 1 - s_i for the human classifier (i=0) and s'_i = s_i for bot classifiers. Platt scaling calibrates the winning score.
Features extracted: over 1,200 features in six categories: metadata, retweet/mention networks, temporal features, content information, and sentiment.
Results¶
In-domain (5-fold cross-validation): ESC achieves AUC 0.96 (vs. 0.97 for Botometer-v3 baseline), showing no loss of in-domain accuracy. Scatter plot of ESC vs. Botometer-v3 scores shows Spearman's ρ = 0.87 agreement.
Cross-domain (hold-out datasets: cresci-rtbust, gilani-17, cresci-stock, kaiser-1/2/3): ESC markedly improves generalization: - F1 improves from 47% to 73% (56% improvement) - Recall increases from 42% to 84% (100% improvement) - Precision increases from 52% to 64% - On combined-test dataset: F1 from 73% to 77% (5% improvement)
The improvement is visualized via bot score distributions: ESC produces higher scores for cross-domain bots while maintaining low scores for humans, reflecting the maximum rule's effect.
Model adaptation: When retraining on a held-out domain (varol-icwsm), ESC reaches target performance with ~300 labeled examples; Botometer-v3 requires ~600. ESC achieves this by adding a new specialized classifier trained from scratch, avoiding the feature selection bias that dominates when retraining the monolithic baseline on small new datasets.
Comparison to tweetbotornot2 baseline: ESC is competitive or superior on most datasets; tweetbotornot2 has slight advantage on kaiser datasets due to preferential weighting of verified accounts.
Connections¶
- Bot detection — directly addresses the bot detection problem
- Cross-domain generalization — demonstrates heterogeneity of bot behaviors as source of generalization failure
- Botometer — deployed in Botometer v4, a widely-used detection tool
- Misinformation amplification — bots spread misinformation; this method improves detection
- Machine learning — ensemble methods, feature engineering, supervised learning
Notes¶
The paper makes a strong empirical contribution: the observation that bot homogeneity within datasets but heterogeneity across datasets drives poor cross-domain recall is well-motivated and clearly demonstrated (Figures 1–3). The ESC solution is elegant and modular—new bot classes simply add new classifiers without retraining existing ones.
The evaluation is thorough: cross-domain testing on six hold-out datasets, comparison to two baselines, analysis of in-domain mislabeling robustness, and model adaptation efficiency. The deployed Botometer v4 reports AUC 0.99 on production data.
Limitations: cross-domain performance is sensitive to dataset choice (acknowledged); the method requires coherent bot class definitions for training, which may not always exist; the maximum rule is heuristic and not principled.