Fighting an Infodemic: COVID-19 Fake News Dataset¶
Authors: Parth Patwa, Shivam Sharma, Srinivas PYKL, Vineeth Guptha, Gitanjali Kumari, Md Shad Akhtar, Asif Ekbal, Amitava Das, Tanmoy Chakraborty
Venue: Springer (FIRE 2020) — DOI
TL;DR¶
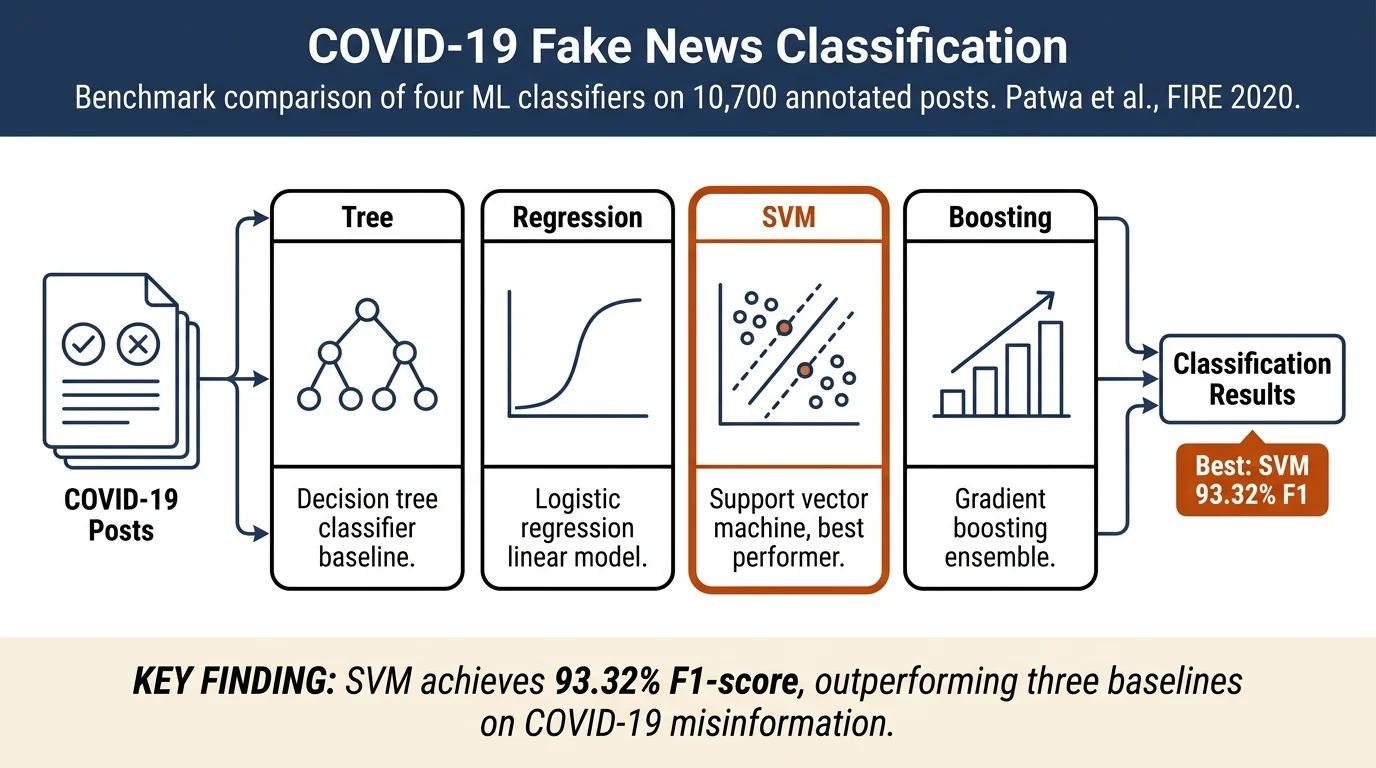
The authors present a manually annotated dataset of 10,700 COVID-19 related posts and articles (52% real, 48% fake) collected from social media and fact-checking websites. They benchmark four machine learning baselines (Decision Tree, Logistic Regression, SVM, Gradient Boost), achieving 93.32% F1-score with SVM, and release both the dataset and code publicly.
Contributions¶
- Dataset: 10,700 manually verified posts/articles labeled as real or fake COVID-19 content
- Data collection methodology: Real news sourced from verified Twitter handles (WHO, CDC, ICMR); fake news from fact-checking websites (PolitiFact, Snopes, NewsChecker, Boomlive)
- Benchmark evaluation: Four ML baselines with comprehensive results across train/validation/test splits
- Public release: Code and data available on GitHub with reproducible experiments
Dataset¶
The dataset contains 5,600 real and 5,100 fake samples split 60% train / 20% validation / 20% test, maintaining class balance across splits. Real news comes from 14 verified sources (government health agencies, news outlets, medical institutions). Fake news is manually verified against fact-checking websites to ensure label accuracy. The authors perform dataset statistics showing real news is longer (avg 31.97 words vs 21.65 for fake), with vocabulary overlap between classes. Only English textual content is included.
Methods¶
The authors use standard preprocessing (removing links, non-alphanumeric characters, stopwords) and TF-IDF feature extraction. Classification experiments employ: - Logistic Regression (LR) - Support Vector Machine (SVM) with linear kernel - Decision Tree (DT) - Gradient Boosting (GDBT)
All models implemented using scikit-learn and tested on a balanced dataset.
Results¶
SVM achieves the best test F1-score of 93.32%, closely followed by Logistic Regression (91.96%). Decision Tree and Gradient Boost report significantly lower F1-scores (85.39% and 86.96% respectively). Performance is consistent between validation and test sets, indicating similar distributions. Precision and recall are balanced across models.
Connections¶
- Complements other multilingual COVID-19 fact-checking work
- Related to Fake news detection as a domain-specific benchmark
- Addresses COVID-19 misinformation detection via supervised learning
- Shares methodology with Rumor detection on social media but focuses on one-off classification rather than stance evolution
Notes¶
This is a solid, pragmatic benchmark for COVID-19 fake news detection during a critical period. The dataset is relatively small by modern standards (10.7K samples) and uses simple ML baselines rather than transformer models, but the clean class balance and public release make it useful for reproducible research. The choice to restrict to English and verified sources ensures label quality, though it limits scope to formal communications rather than the full spectrum of social media discourse. Future work correctly identifies enriching with reasoning labels and exploring deep learning as natural extensions.