TextAttack: A Framework for Adversarial Attacks, Data Augmentation, and Adversarial Training in NLP¶
Authors: John X. Morris, Eli Lifland, Jin Yong Yoo, Jake Grigsby, Di Jin, Yanjun Qi Venue: arXiv — arXiv
TL;DR¶
Introduces TextAttack, an open-source Python framework unifying 16 adversarial attacks from the literature into a modular architecture for testing and improving NLP model robustness. The framework decomposes attacks into four reusable components (goal function, constraints, transformation, search method), enables benchmarking attacks on standardized models and datasets, and supports data augmentation and adversarial training. With 82+ pre-trained models integrated via HuggingFace, TextAttack significantly reduces barriers to adversarial robustness research.
Contributions¶
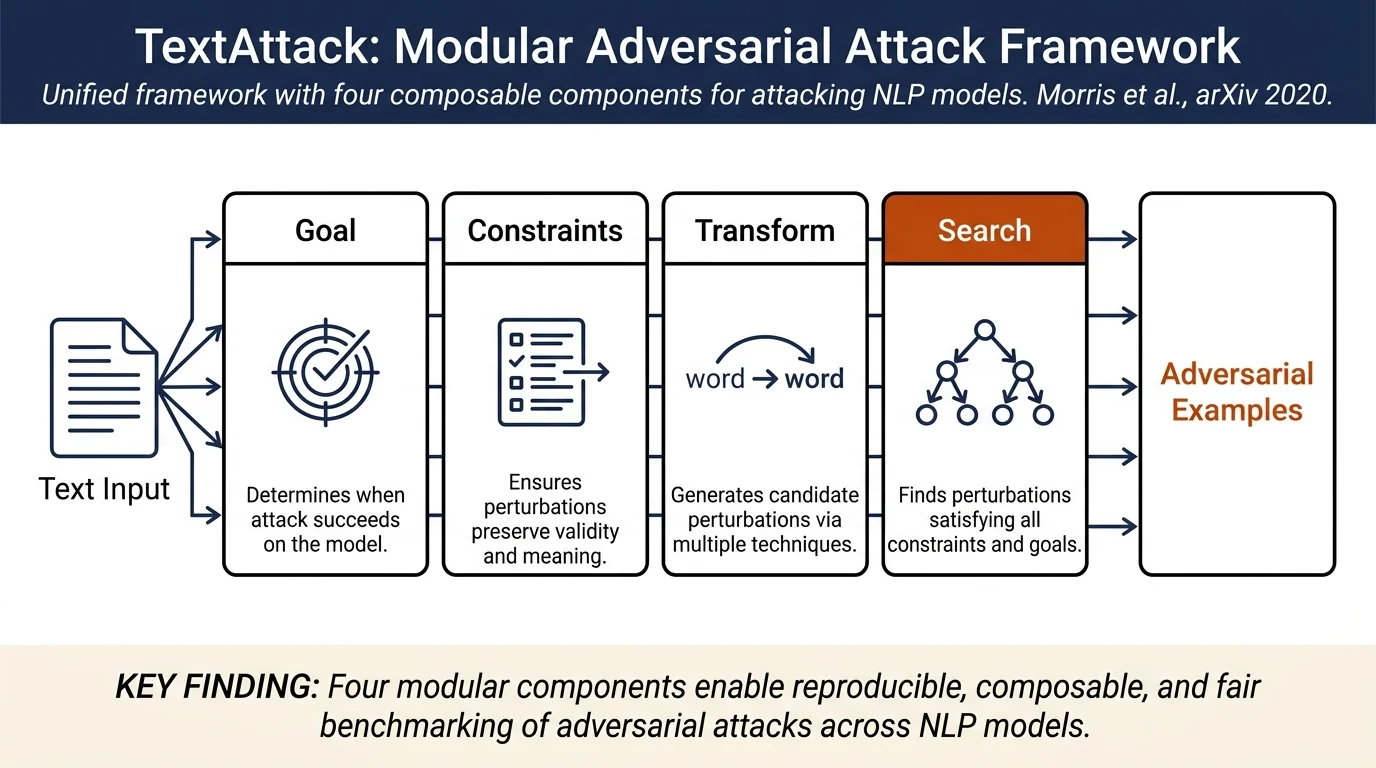
- Modular framework for adversarial attacks decomposing NLP attacks into four composable components: goal function (success criteria), constraints (validity requirements), transformation (perturbation generation), and search method (combinatorial optimization).
- Attack recipes for 16 state-of-the-art adversarial attacks from the literature, enabling reuse of components and reproducible benchmarking across models and datasets.
- Integration with 82+ pre-trained models (LSTM, CNN, BERT, RoBERTa, etc.) via HuggingFace transformers, supporting evaluation across diverse architectures and datasets.
- Data augmentation toolkit for generating adversarial training data via pre-implemented attack recipes.
- Adversarial training pipeline enabling in-loop generation and periodic training of models on augmented data.
- Unified evaluation framework for comparing attack success rates across different search methods, transformations, and goal functions.
Method¶
TextAttack decomposes each adversarial attack on an NLP model into four components:
1. Goal Function. Determines whether an attack is successful based on model outputs. Examples: untargeted classification (minimize score of original label), targeted classification (maximize score of target label), input reduction (minimize number of perturbed words), text-to-text tasks (minimize BLEU/METEOR distance from original output).
2. Constraints. Define validity requirements that perturbations must satisfy. Categories include: - Pre-transformation constraints (e.g., stopword modification, part-of-speech consistency) - Semantic constraints (e.g., maximum word embedding distance, minimum sentence-level similarity) - Grammaticality constraints (e.g., maximum grammatical errors measured by LanguageTool, part-of-speech tag matching)
3. Transformation. Generates potential perturbations. TextAttack supports white-box (access to model gradients) and black-box transformations: - White-box: word swaps by gradient (maximize model loss), nearest embedding neighbors - Black-box: word swaps via language model, character-level perturbations (insertion, deletion, substitution, neighboring character swaps), word deletion, composite transformations
4. Search Method. Finds perturbations satisfying all constraints and achieving the goal. Implemented methods: - Greedy word importance ranking: swap words one-at-a-time by decreasing importance - Beam search: maintain top-b candidate transformations, iteratively expand - Genetic algorithm: population-based evolutionary search - Particle swarm optimization: population-based velocity-driven search
Results¶
Attack Reproduction. TextAttack successfully reproduces 16 attacks from prior work on multiple datasets:
| Attack | Goal | Baseline | Success (TextAttack) |
|---|---|---|---|
| BERT-Attack (Li et al., 2020) | Untargeted | 77.30% | 66.67% |
| BAE (Garg & Ramakrishnan, 2020) | Untargeted | 78.2% | 72.1% |
| TextFooler (Jin et al., 2019) | Untargeted | 94.89% | 92.84% |
| DeepWordBug (Gao et al., 2018) | Untargeted | 86.37% | 82.63% |
Variations in success rates reflect implementation differences (e.g., different embedding models, constraint implementations) versus the original papers.
Adversarial Training. Augmenting an LSTM model's training set with adversarial examples generated by TextAttack significantly improves robustness: - Baseline LSTM trained on clean rotten_tomatoes dataset: 77.30% accuracy - LSTM trained with EDA augmentation: 71.7% accuracy (after textfooler attack) - LSTM trained with TextAttack augmentation: 62% accuracy (after textfooler attack; shown in Figure 4 with 95% confidence intervals)
The augmentation maintains generalization to clean test sets while improving adversarial robustness.
Connections¶
- Extends adversarial robustness research from computer vision to NLP via unified evaluation framework, enabling fair benchmarking of attack methods
- Relates to NLP robustness and model evaluation by providing standardized benchmarks across GLUE tasks
- Foundational for adversarial training techniques that improve model generalization and out-of-distribution robustness
- Complements data augmentation methods (EDA, easy data augmentation) by providing automated generation of adversarial training examples
- Enables comparative analysis of adversarial examples across search methods (genetic, particle swarm, beam search) and attack families
- Supports evaluation of language model robustness including BERT-family models
Notes¶
TextAttack significantly lowers the barrier to entry for adversarial robustness research by providing reusable components and pre-trained model integration. The modular design enables researchers to focus on novel components (e.g., new transformations or search methods) rather than reimplementing baseline infrastructure. The framework's breadth (16 attacks, 82+ models, multiple datasets) enables fair cross-paper comparisons previously hindered by heterogeneous evaluation protocols. Limitations include: (1) tokenization differences between papers' original implementations and TextAttack can lead to success rate variance, (2) primarily supports input-level perturbations, not structural attacks, (3) black-box search methods are computationally expensive compared to gradient-based approaches. The code and tutorials are available at https://github.com/QData/TextAttack, substantially supporting the framework's adoption and contribution to standardizing adversarial robustness evaluation in NLP.