Language Models are Few-Shot Learners¶
Authors: Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei
Venue: NeurIPS 2020 — ArXiv
TL;DR¶
This landmark paper introduces GPT-3, a 175-billion-parameter autoregressive language model, and demonstrates that it achieves strong performance on diverse NLP tasks through in-context few-shot learning without any task-specific fine-tuning. The model exhibits remarkable scaling properties where larger models dramatically improve few-shot performance. Critically, the authors document that GPT-3 can generate synthetic news articles that are difficult for humans to distinguish from human-written articles, raising important concerns about AI-generated misinformation.
Contributions¶
-
GPT-3 architecture and training. Presents a 175B parameter transformer language model trained on 300 billion tokens from diverse sources (Common Crawl, Books1, Books2, Wikipedia, WebText2).
-
Few-shot learning without gradient updates. Demonstrates that language models can perform tasks with only a handful of in-context examples and natural language instructions, without any parameter updates or fine-tuning.
-
Comprehensive evaluation across diverse tasks. Evaluates GPT-3 on 42 language understanding and generation benchmarks spanning language modeling, cloze completion, translation, question answering, arithmetic, common-sense reasoning, and reading comprehension.
-
Scaling laws analysis. Shows that few-shot learning performance scales smoothly as a power law with model capacity, and that larger models more efficiently utilize in-context information.
-
Data contamination analysis. Systematically studies the impact of training data overlap with benchmark test sets and identifies datasets where such overlap occurs.
-
Synthetic text generation and societal impacts. Documents that GPT-3 can generate coherent multi-paragraph news articles that human evaluators find difficult to distinguish from real news, and discusses broader implications for misuse.
Method¶
GPT-3 uses the same transformer architecture as GPT-2, with modifications to improve efficiency (e.g., sparse attention). The model is trained with dense and locally banded sparse attention patterns.
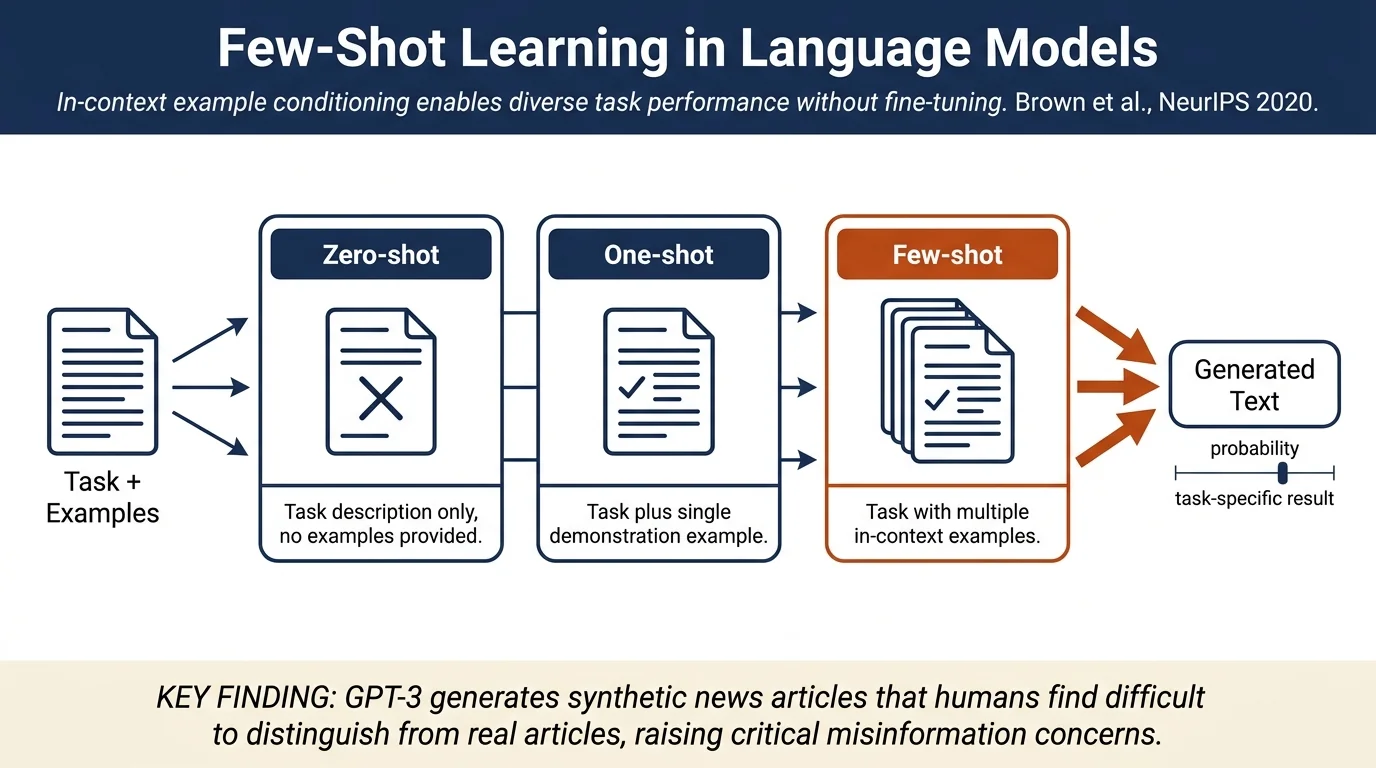
Three learning paradigms are evaluated:
-
Zero-shot: Only a natural language description of the task, no demonstrations.
-
One-shot: A single example of the desired task.
-
Few-shot: Typically 10-100 in-context examples where the model is conditioned on the natural language task description and examples, then predicts the completion.
Training uses the Common Crawl dataset (preprocessed and filtered for quality) combined with curated datasets (Books1, Books2, Wikipedia, WebText2). The model is trained for a total of 300 billion tokens across 8 models ranging from 125M to 175B parameters.
Results¶
Few-shot performance. Across 42 diverse NLP benchmarks, GPT-3 achieves competitive or state-of-the-art few-shot results. Key findings include:
-
Language modeling: GPT-3 achieves 20.50 perplexity on PTB, substantially improving over the SOTA baseline (35.8).
-
Cloze and completion tasks: On LAMBDA, GPT-3 achieves 86.4% accuracy in few-shot settings, improving significantly over the previous state-of-the-art (68% SOTA zero-shot). On StoryClose (cloze), few-shot GPT-3 achieves 87.7% accuracy.
-
Question answering: On TriviaQA, GPT-3 achieves 71.2% F1 in the few-shot setting. On multiple open-domain QA benchmarks, few-shot GPT-3 outperforms fine-tuned models.
-
Translation: GPT-3 demonstrates few-shot translation capability across multiple language pairs (English↔French, English↔German, English↔Romanian), with BLEU scores showing consistent improvement with model size and number of examples.
-
Reading comprehension: On RACE, GPT-3 achieves 85.2% accuracy in few-shot setting (only slightly below fine-tuned SOTA).
-
Scaling properties: Few-shot performance scales dramatically with model size; large models show steep improvements while smaller models plateau. The performance curve follows a smooth power-law trend.
Synthetic news generation. Most critically for misinformation research, GPT-3 can generate multi-paragraph news articles when given a news prompt. Human evaluators found it "difficult" to distinguish GPT-3-generated articles from real ones written by humans, indicating strong synthetic text generation capability.
Connections¶
- Related to Language Models and the broader category of Large Language Models.
- Foundational for understanding In-Context Learning and Few-Shot Learning.
- Directly relevant to Synthetic Text Generation and AI-Generated Content.
- Cited by nearly every subsequent work on large language models and in-context learning.
Notes¶
This paper is a watershed moment in NLP research for two reasons: (1) the demonstrated scale of in-context learning without fine-tuning, which shifted the research agenda away from task-specific architectures toward prompting and retrieval, and (2) the explicit discussion of synthetic news generation and the difficulty humans have in distinguishing machine-generated from human-written news.
The authors are admirably transparent about data contamination issues and acknowledge limitations—GPT-3 struggles on tasks requiring rapid adaptation (like few-shot mathematical reasoning). The synthetic news generation capability is documented but not extensively explored; the paper briefly mentions it in Section 6.2 (Broader Impacts) without deep characterization of failure modes or detectability.
For the fake news wiki, the most relevant finding is the documented ability to generate synthetic news articles. This capability is foundational to understanding modern AI-driven misinformation risks, though this paper predates systematic work on detecting AI-generated text or mitigating its spread.