Tree LSTMs with Convolution Units to Predict Stance and Rumor Veracity in Social Media Conversations¶
Authors: Sumeet Kumar, Kathleen M. Carley
Venue: ACL 2019 (57th Annual Meeting of the Association for Computational Linguistics), pages 5047–5058, Florence, Italy — July 28–August 2, 2019
TL;DR¶
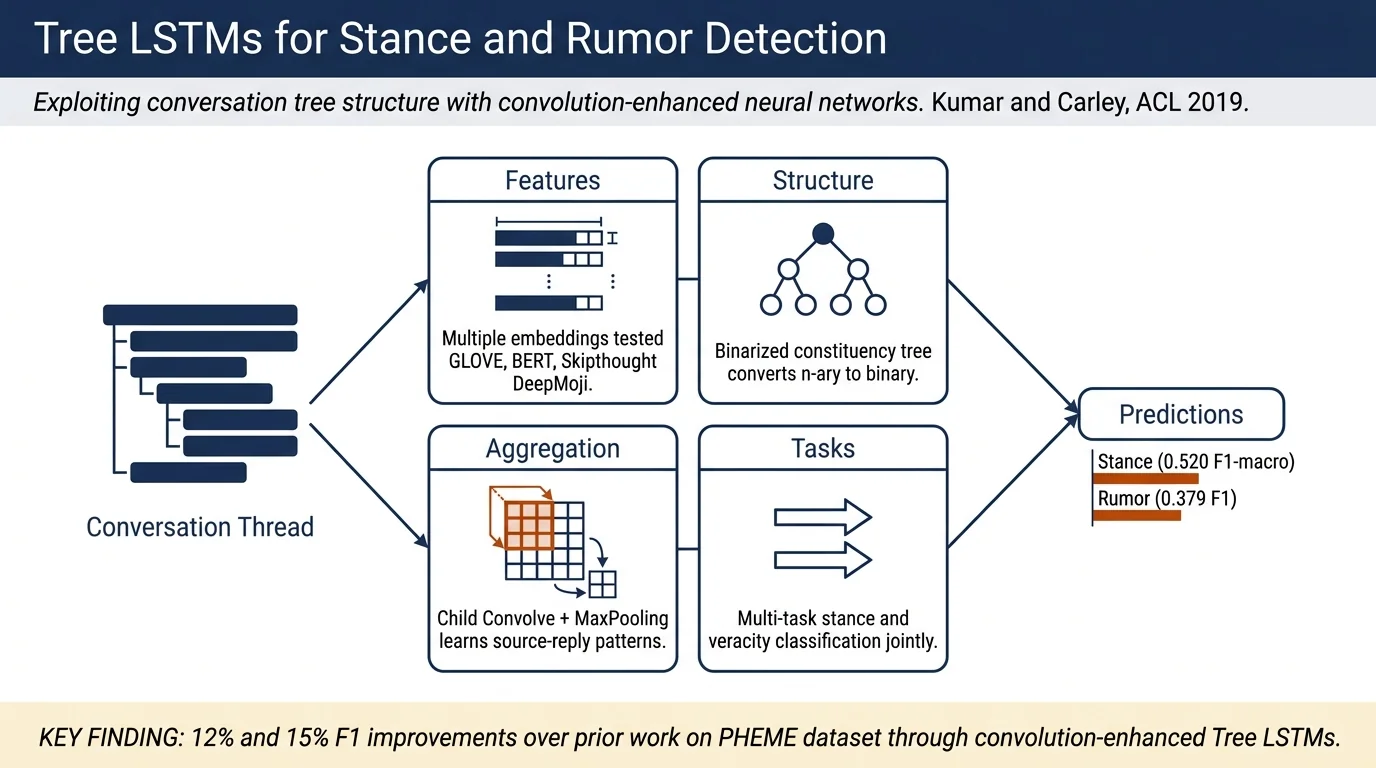
Proposes Tree LSTM and Binarized Constituency Tree (BCTree) LSTM architectures enhanced with convolution units to classify stance and predict rumor veracity in social media conversation threads. The approach exploits the tree structure inherent in threaded conversations (source post with nested replies) and combines it with convolutional operations to learn source-reply contrasts; achieves 12% and 15% F1-score improvements on the PHEME dataset over prior work for stance and rumor classification respectively using multi-task learning.
Contributions¶
- New representations of social media conversation trees, particularly the Binarized Constituency Tree (BCTree) structure where source posts and replies become leaf nodes paired with a virtual parent node, enabling consistent binary tree operations for neural networks.
- Convolution units integrated into Tree LSTMs (Child Convolve, Child Convolve + MaxPooling, Child Convolve + Concat variants) that learn local patterns in source-reply feature comparisons more effectively than sum or max-pooling aggregation alone.
- Multi-task learning formulation jointly optimizing stance classification (SDQC labels on each reply) and rumor veracity classification (true/false/unverified on root post) showing complementary signal between tasks.
- Comprehensive evaluation of multiple feature representations (GLOVE, BERT, Skipthought, DeepMoji, SKPEMT) demonstrating that convolution-based Tree LSTM models outperform branch-based and text-only baselines.
Method¶
Problem Framing¶
The paper models social media conversations as rooted trees where the source tweet is the root and reply tweets are child nodes at various depths. Two key modeling decisions:
-
Tree LSTM Model: Uses tree structure directly; at each non-root node, the LSTM processes the reply text and latent vectors from all child replies (via a Child Sum aggregation). Multi-task learning: latent vectors at each node predict stance labels (support/deny/query/comment) while the root node's latent vector predicts rumor veracity.
-
Binarized Constituency Tree (BCTree) LSTM: Converts the general n-ary tree into a binary tree where each source post and reply becomes a leaf node, and a virtual parent node aggregates two children. This preserves the original structure while enabling consistent binary operations across all nodes. Beneficial for tasks like stance learning where comparing reply against source (not intermediate nodes) is important.
Architecture Details¶
Child Aggregation Units: The paper proposes three variants for combining child hidden states: - Child Sum: $ \bar{h} = \sum_{k \in C(j)} h_k $ - Child Max-Pooling: $ \bar{h} = \max_{k \in C(j)} h_k $ - Child Convolve + Max-Pooling: $ \bar{h} = \max_{*} \otimes_{k \in C(j)} h_k $ where \(\otimes\) is vector convolution and \(\max_*\) is max-pooling; learned stride and kernel preserve dimensionality.
Feature Representation: Tested five embedding methods: - GLOVE: pretrained word vectors, sentence embedding as mean of word vectors - BERT: fine-tuned on Multi-Genre NLI task; outputs 768-dim vectors - Skipthought: 4,800-dim unsupervised skip-gram sentence encoding - DeepMoji: 64-dim emoji prediction-based representation - SKPEMT: concatenation of Skipthought + DeepMoji + BERT (4,864 dims)
Training: Stochastic gradient descent with cross-entropy loss; multi-task loss = stance loss + rumor loss (alternating between tasks during training); hidden dimension 64; learning rate 0.008; 30 epochs. Balanced minority classes via oversampling for rumor, duplicate nodes for stance.
Results¶
Stance Classification (Table 3): - Tree LSTM with Child Convolve + MaxPooling and SKPEMT features: 0.520 mean F1-macro across five PHEME events (Charlie Hebdo, Sydney siege, Ferguson, Ottawa shooting, Germanwings crash) - Improves over prior work (Zubiaga et al., Kochkina et al.) by ~12% F1-macro - Best at classifying 'Comment' (0.84 F1) and 'Support' (0.62 F1); struggles with 'Deny' (0.31 F1) due to class imbalance
Rumor Classification (Table 4): - Tree LSTM with Child Convolve + MaxPooling and SKP features: 0.379 mean F1 across events - Improves by ~15% F1-macro over prior work (Kochkina et al., NileTMRG) - BCTree LSTM slightly underperforms Tree LSTM (0.371 mean F1), likely due to added virtual nodes obscuring class balance
Feature Type Analysis: - SKPEMT (concatenated features) consistently outperforms individual representations - Skipthought performs well relative to its dimensionality (4800 dims) - GLOVE underperforms (0.329 mean F1 for stance), suggesting pretrained embeddings insufficient for task
Connections¶
- Builds on Zubiaga et al.'s foundational work using tree structure for rumor conversations, extending it with neural methods rather than CRFs.
- Related to Kochkina, Liakata & Augenstein (2017)'s Branch-LSTM for stance, which processes conversation branches sequentially; this work exploits full tree topology.
- Addresses multi-task learning for rumor detection building on Kochkina & Zubiaga (2018)'s multi-task framework showing auxiliary tasks improve veracity classification.
- Uses PHEME dataset introduced in Zubiaga et al. (2015) with extensions for stance labels; dataset used in RumourEval shared tasks (Derczynski et al. 2017, Gorrell et al. 2019).
- Employs convolutional operations in neural networks for NLP, extending Kim (2014)'s CNN text classification to hierarchical tree structures.
Notes¶
Strengths: - Comprehensive feature ablation across five representation methods; clear demonstration that feature choice substantially impacts performance. - Honest about BCTree underperformance despite conceptual motivation for binary structure; likely due to class imbalance exacerbation in newly added virtual nodes. - Multi-task learning showing complementary benefits between stance and rumor tasks, with alternating training strategy. - Addresses a genuine limitation of prior work: while Branch-LSTM processes branches sequentially, this work leverages the full tree structure.
Weaknesses: - PHEME dataset has severe class imbalance, particularly in the rare 'Deny' and 'Query' stance classes; oversampling is a crude remedy and results show poor performance on these classes. - No early detection analysis (e.g., performance with partial conversations); practical deployment requires timely classification on incomplete threads. - Limited error analysis; confusion matrix shown only for rumor classification, not stance; no qualitative examples of where models fail. - Scalability not addressed; Tree LSTMs require tree topology but social media platforms often produce shallow, wide trees; unclear how deep/bushy conversation trees affect computational cost. - No comparison of Tree LSTM to simpler baselines (e.g., bag-of-words averaging of all replies, or attention over reply sequence without tree structure).
Follow-up work: - Exploration of pre-trained language models (BERT fine-tuning) which have shown large gains in subsequent stance/veracity work. - Early detection with time-aware representations, predicting veracity before conversation fully matures. - Cross-domain transfer; PHEME covers news events; generalization to other domains (health, politics) unclear. - Interpretation of learned convolution filters: what source-reply patterns do they capture?